

1. 서 론
대부분의 철강업체들은 세계적 철강공급 과잉으로 인해 생산원가를 줄이기 위해 지속적인 개선을 추진하고 있다. 철강, 석유화학, 발전, 가스플랜트 등과 같이 연속생산 체계로 운영되는 장치산업(process industry)의 경우 전체 생산비용 중 15~25%가 사전, 사후설비보전 등에 사용되며, 공급과잉 시장환경에서 설비보전 비용 절감은 그 어느 때 보다 중요한 문제로 대두되고 있다(Yacout, 2010). 장치산업에서 비계획정지(unscheduled breakdown)가 발생할 경우, 생산성 하락은 물론 생산중이던 제품과 생산 대기중인 중간제품까지 품질변동 발생하여 정상제품으로 생산이 불가능하게 된다. 따라서, 장치산업에서 균일한 품질의 제품을 연속적으로 생산하기 위해서는 설비상태를 모니터링하여 실시간으로 진단(diagnosis)하고 사전에 설비장애를 예지(prognosis)하여 사전에 조치하는 것이 무엇보다 중요하다.
최근 설비에 설치된 센서를 통해 얻어진 정보가 서로 연결되는 사물인터넷(Internet of things, IoT)기술이 발달하고, 하둡(hadoop)과 같은 대용량 데이터장치가 구현됨에 따라 저렴한 비용으로 대량을 데이터를 수집할 수 있게 되었다. 또한 성능이 우수한 기계학습(machine learning), 딥러닝(deep learning) 알고리즘의 개발로 철강산업에서의 설비보전관리는 일대 전환기를 맞고 있다. 고장예지 및 건전성 관리(prognostics and health management, PHM)는 공학시스템의 실사용 환경에서 다양한 센서를 통해 데이터를 수집, 관찰하여 설비의 이상상태를 진단하고, 설비수명을 예지하여 필요 정비를 필요한 때, 필요한 만큼 실시하는 관리하는 기술이다. 이러한 PHM 기술을 이용하여 스마트한 설비보전으로 빠르게 패러다임 전환이 이루어지고 있다(Lee and Yun, 2015).
본 논문에서는 설비이상 유무의 레이블(label)이 없는 설비 데이터를 이용하여 설비상태의 변화를 진단하는데 초점을 둔다. 철강생산공정에서는 다양한 센서, 측정기, PLC, 그리고 제어값을 계산하는 프로세스 컴퓨터 등을 이용하여 대량의 조업 데이터가 생성, 저장된다. 설비장애가 자주 발생하지 않는 장치산업의 특성상 수집된 대부분의 데이터는 설비가 정상상태일 때 수집된다. 따라서, 수집된 데이터의 대부분은 정상이며 설비의 이상을 나타내는 비정상 데이터의 양은 매우 적은 특징을 가진다. 설비이상 여부에 대한 문제를 머신러닝 관점에서 보면 다양한 조업변수(operation parameter)와 설비변수(equipment parameter)를 원인인자로 하고 설비 이상유무를 판단하는 전형적인 분류(classification) 문제이다. 그러나, 설비에서 수집된 데이터에 레이블이 주어지지 않는 경우에는 분류모형의 알고리즘을 사용할 수 없으므로 비지도학습(unsupervised learning)을 기반으로 군집분석(cluster analysis)을 시행하게 된다. 이것은 정상 제품을 생산할 때 설비의 상태를 정상으로 가정하고, 군집분석 결과 지금까지 수집된 데이터의 군집과 다른 새로운 군집이 나타날 경우 설비의 상태가 현재와 달라졌다고 판단하고 설비를 점검하게 된다.
본 논문에서는 비지도학습 또는 반지도학습(semi-supervised learning)으로 사용 가능한 오토인코더(autoencoder)를 사용하여 학습된 과거 상태와 달라진 상태를 모니터링한다. 전통적인 신뢰성 분석(reliability analysis)은 일반적으로 고장시간 데이터와 확률분포에 기반하여 설비수명을 예측하지만, 설비에서 발생하는 데이터를 기반으로 오토인코더를 사용하여 설비상태 변화를 모니터링 할 수 있음을 보인다.
2. 선행연구
설비상태 모니터링의 목적은 설비가 운전중일 때 계측된 신호를 이용하여 설비의 상태를 진단하고 결함여부를 파악하여 예지보전을 위한 유용한 정보를 제공하는 것이다. 설비의 진동을 이용한 상태감시는 1970년대부터 시작되어 많은 산업분야에서 적용되고 있으며, 최근 머신러닝 기법을 이용한 상태감시 관련 연구가 활발하게 이루어지고 있다. Choi(2013)의 자료에 의하면 설비상태진단 및 예지 관련 연구는 주로 경험기반방법(experience based approach), 데이터기반방법(data-driven approach), 모델기반방법(model based approach)로 나뉘어 연구되고 있다. 경험기반방법은 시험 또는 가동중에 얻어진 고장데이터를 이용하여 통계처리 후 수명예측에 활용한다. 고장데이터를 와이블(Weibull)분포와 같은 확률분포에 적합 후 수명을 추정하고, MTBF(mean time between failure)를 결정한다. 이 방법은 적용범위가 넓고 적용이 간단한 장점이 있지만, 고장데이터가 많아야 하며 동일한 조건과 고장에 대해서만 사용가능하고 실시간 결함모니터링이 아니라는 단점이 있다. 데이터기반방법은 수집된 데이터를 기반으로, 머신러닝기법을 이용하여 설비이상 및 손상정도를 학습 후 온라인 모니터링에 적용한 뒤, 미래고장을 외삽(extrapolation)하여 예측한다. 이 방법은 물리모델 없이도 사용가능하여 적용범위가 넓은 장점이 있으나 학습을 위해 많은 데이터(massive run-to-failure data)가 필요하며 사용조건이 다르면 다시 학습을 해야한다. 또한, 근접 예측은 가능하나 먼 미래예측은 신뢰하기 어려운 단점이 있다. 마지막으로 모델기반 방법은 물리적 고장메커니즘기반모델 (physics of failure based degradation model)을 활용하여 온라인 건전성 데이터를 활용하여 손상모델을 실시간 업데이트하고 미래를 예측하는 방법이다. 적은 고장데이터로도 예측 정확도가 높고, 먼 미래의 고장예지도 가능하지만 확립된 고장물리 모델이 많지 않아 적용분야가 제한적이다.
데이터기반방법에도 학습방법에 따라 지도, 반지도, 비지도학습으로, 사용 알고리즘에 따라 머신러닝과 딥러닝으로 나뉜다. 먼저, Hansson et al.(2016)은 중화학공업에서의 머신러닝을 활용에 대한 체계적 연구를 수행하였는데, 지도학습과 비지도학습으로 진단 방법론을 나누고 분류기로 다층퍼셉트론(multilayer perceptron), 서포트벡터머신(support vector machine), 의사결정트리(decision tree), 랜덤포레스트(random forest) 및 메타알고리즘(meta algorithm)으로 배깅(bagging)과 부스팅(boosting)의 적용사례를 연구하였다. 성능지표(performance index)로서 문턱값 척도(threshold metrics), 순위척도(rank metric), 확률척도(probability metric)를 제시하고, 정확도(accuracy), AUC(area under the curve), 평균제곱합오차(MSE)의 장단점을 제시하였다. Omar(2013)는 비정상탐지(anomaly detection) 문제를 해결하기 위해 지도학습과 비지도학습을 적용방안에 대한 비교연구를 실시하였다. Ahmad et al.(2017)와 Devika(2014)는 시계열 데이터의 비정상탐지를 위해 비지도학습방법을 이용한 연구를 수행하였다. Farina et al.(2015)는 철강생산설비에서 얻어진 시계열 데이터를 Hotelling의 관리도를 기반으로 기어박스의 베어링 고장을 탐지하는 방법을 제안한 바 있다. 또한, Seo and Yun (2017)은 설비에서 얻어진 시계열데이터를 이용하여 비지도학습을 이용하는 군집기반 설비 상태 모니터링을 제안하였다. 설비이상 모니터링을 위해 유클리드 거리와 마할라노비스 거리(Mahalanobis distance)를 사용하는 K-means과 PAM(partition around medoids)의 성능을 비교 후, 군집기반 설비이상을 모니터링하는 절차를 제안하였으며, 정규분포와 같은 특정한 분포를 가정하는 다변량관리도(multi-variate control chart)가 설비이상 진단에 사용될 경우 성능이 제한적임을 지적한 바 있다. 유사한 연구로, Kumar et al.(2010)는 마할라노비스 거리를 이용한 전자제품의 이상을 규명하는 연구를 수행하였다.
최근 몇 년 동안, 패턴인식(pattern recognition)에 관한 연구에서 딥러닝(deep learning) 알고리즘이 두각을 나타내고 있는데 이 방법은 인간 두뇌의 학습 과정을 모방하는 효과적인 방법으로 여러 비선형변환(nonlinear transformation)을 통해 원시데이터(raw data)에서 대표 특징(feature)을 찾아내는데 탁월한 성능을 보여주고 있다. 특히, 딥러닝의 뛰어난 패턴인식 성능을 이용하여 설비의 건전성을 평가하고 판단하는 성공적인 사례가 보고되고 있다(Sakar et al. 2016). 특히, 오토인코더를 활용한 연구가 활발하다. Vincent et al.(2010)는 항공기엔진 고장진단을 위한 패턴추출기로 적층잡음제거 오토인코더(stacked denoising autoencoder)를 사용하고, 소프트맥스 분류기(soft-max classifier)를 이용하여 결함을 분류하는 연구를 수행하였다. Shao et al.(2017)은 회전기계의 고장진단을 위해 오토인코더를 적용하고, 새로운 손실함수를 제안한 후 기어박스결함에 대한 시험장비에서 추출한 진동 데이터를 사용하여 고장진단에서 유용한 결과를 도출하였다. Zhu et al.(2015)의 연구에서는 유압펌프에 적층오토인코더(stacked autoencoder)를 적용하여 별도의 패턴추출 과정 없이 펌프의 비정상 상태를 진단 할 수 있음을 보였다. Zhou et al.(2015)는 공정의 상태를 분류하기 위해 사출성형 공정에 k-NN과 희소오토인코더(sparse autoencoder)를 적용한바 있다. Hu et al.(2016)은 설비예지 및 건전성 관리에 대한 응용을 위해 설비데이터 패턴에서 특징추출을 위한 딥러닝 방법을 제안한 바 있다.
본 연구에서는 철강생산 설비가 정상적으로 무부하구간에서 운전중일 때 진동데이터를 수집하여 오토인코더 모델을 학습한다. 이후 설비이상이 예상되는 검증데이터에서 시간영역 특징을 추출하여 입력했을 때, 학습된 오토인코더 기준모델이 나타내는 재구성오차와 시험데이터의 입력으로 얻어지는 재구성오차의 차이를 이용하여 설비가 이전 상태와 달라졌는지 여부를 판단할 수 있음을 보인다. 그리고, 정상상태 데이터와 시험 데이터를 이미지화하여 직관적으로도 확인할 수 있음을 보인다.
논문의 나머지 부분은 다음과 같이 구성된다. 3 장에서는 열간 조압연 공정과 데이터 구성을 소개하고 4장에서는 설비상태를 모니터링하기 위한 인공신경망 모델인 오토인코더 활용 방법을 설명한다. 5장에서는 적용 방법의 유효성을 검증하기 위해 현장 데이터에서 시간영역 특징을 추출하여 분석하고, 6장에서는 연구결과를 요약 후 설비이상에 대한 사전진단의 중요성과 향후 연구 방향에 대해 논의한다.
3. 열간 조압연 공정 및 데이터 구성
3.1 열간 조압연 공정
열간조압연 공정은 철강공정에서 열연코일 완제품 혹은 냉연제품을 생산하기 위한 중간재를 생산하는 중요한 공정이다. 또한 열연제품의 가공품질은 후공정의 통판성과 품질을 좌우하게 되므로 중간공정으로서 역할이 매우 중요하다. 열연공정은 <Figure 1>에 도시된 바와 같이 가열(heating), 조압연(roughing mill), 마무리 압연(finishing mill), 냉각(cooling) 및 권취(coiling)공정으로 나눌 수 있다. 조압연공정은 열연공정의 중간재인 바(bar)를 생산하며, 재결정온도(re-crystallizing temperature)이상으로 가열된 슬라브(slab)를 마무리 압연에 적합한 크기와 형상으로 압연한다. 압연설비가 비계획 정지시 가열로에서 추출된 슬라브는 대기중에서 급속히 냉각되므로 재열처리(reheating)과정이 필요하다. 또한, 가열로 내에서 가열중인 슬라브 또한 적당한 시점에 인출되지 못하게 되면 품질 불균일의 원인이 된다. 공정 특성상 운전중 설비에 정비원이 접근하여 설비상태를 직접 점검하기 불가능하므로 설비로부터 측정되는 데이터를 통해 설비이상을 진단하는 것이 필수적이다. 조압연기는 두꺼운 슬라브를 마무리압연이 가능한 두께와 폭으로 가공하므로 상대적으로 큰 부하를 받는 설비이다. 따라서 조압연기 이상유무에 대해 신속하게 판단하고, 계획 수리시 조치가 필요하다. <Figure 2>는 조압연기의 기계적 구조(왼쪽)와 제품을 생산하고 있는 현장 사진(오른쪽)을 보여주고 있다. 본 연구에서는 조압연기의 상태진단을 위해 수집되는 진동 계측기 정보를 가공, 분석을 실시하여 정상상태와 이상상태를 구분하고자 한다. 이를 통해 설비의 계획되지 않은 중단을 미연에 방지하고 필요할 경우 필요한 만큼의 예지보전을 실시하여 비계획 설비중단으로 인한 손실을 최소화하는 것을 목적으로 한다.
3.2 데이터의 구성 및 특징
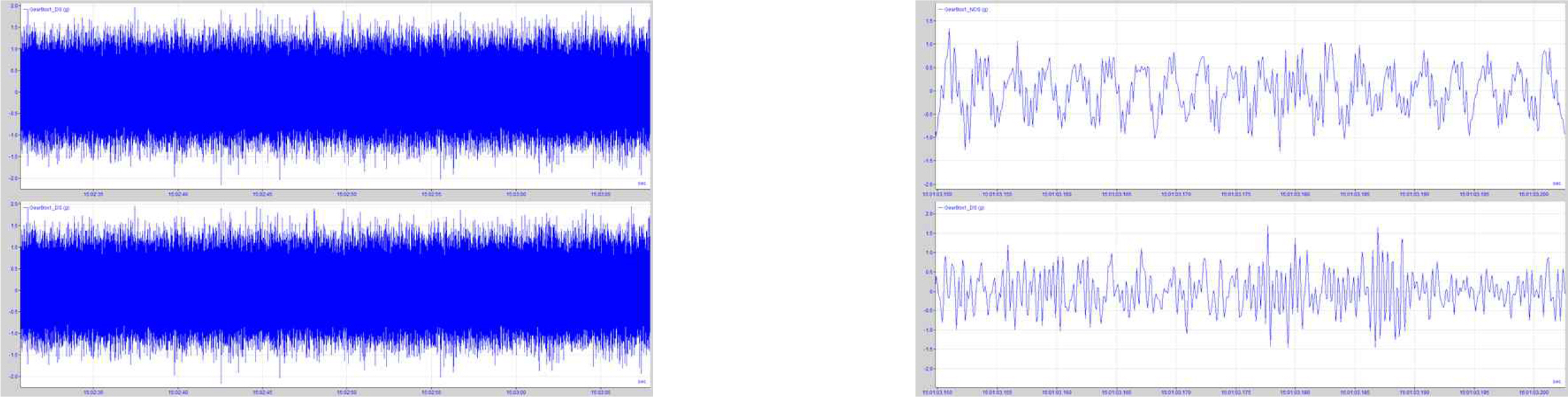
본 논문에서는 열간조압설비의 기어박스 진동센서에서 얻어지는 가속도, 속도, 변위 데이터를 수집하고 이 중에서 가속도 데이터를 분석에 사용하였다. 가속도의 경우 설비가 받는 힘의 크기를 직접적으로 나타내므로 설비상태를 진단하는데 적합하다. 조압연 설비에 압연소재가 롤에 물려 들어갈 때는 충격부하에 의한 큰 진동이 발생하고 압연중에는 소재온도의 불균일 분포에 따라 압하력이 불규칙적으로 변동하게 된다. 이때 발생하는 설비 데이터에서는 패턴을 찾거나 설비 이상유무를 진단하기는 매우 어렵다. 따라서, 하나의 소재가 압연되고, 다음 소재의 압연을 준비할 때 등속으로 운전되는 무부하로 운전되는 구간의 데이터만 분석에 사용할 필요가 있다. 본 논문에서는 설비가 소재를 가공하지 않고 일정한 속도로 운전되는 무부하구간 데이터를 이용하여 설비변동을 모니터링하고 진단하는 것을 목적으로 한다. <Figure 3>의 왼쪽에서 보는 것은 축소된 시험설비에서 수집된 원천데이터이다. 데이터 수집주기가 매우 짧아 원천데이터 자체에서 직관적으로 중요한 특징이나 변화를 찾아내기 어렵다. <Figure 3>의 오른쪽 그림은 원천데이터를 확대한 것으로 수집된 데이터는 시간의 흐름에 따라 시간영역 성분과 주파수영역 성분들이 변화하고 있음을 확인할 수 있다.
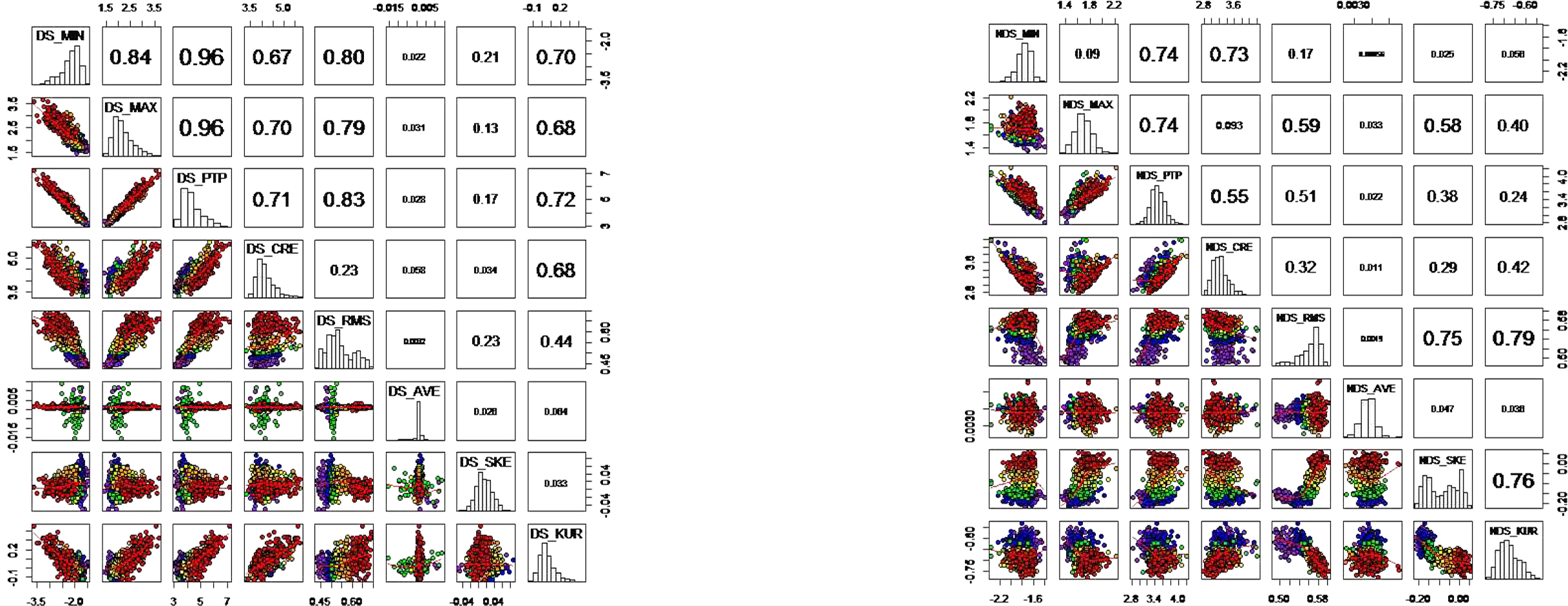
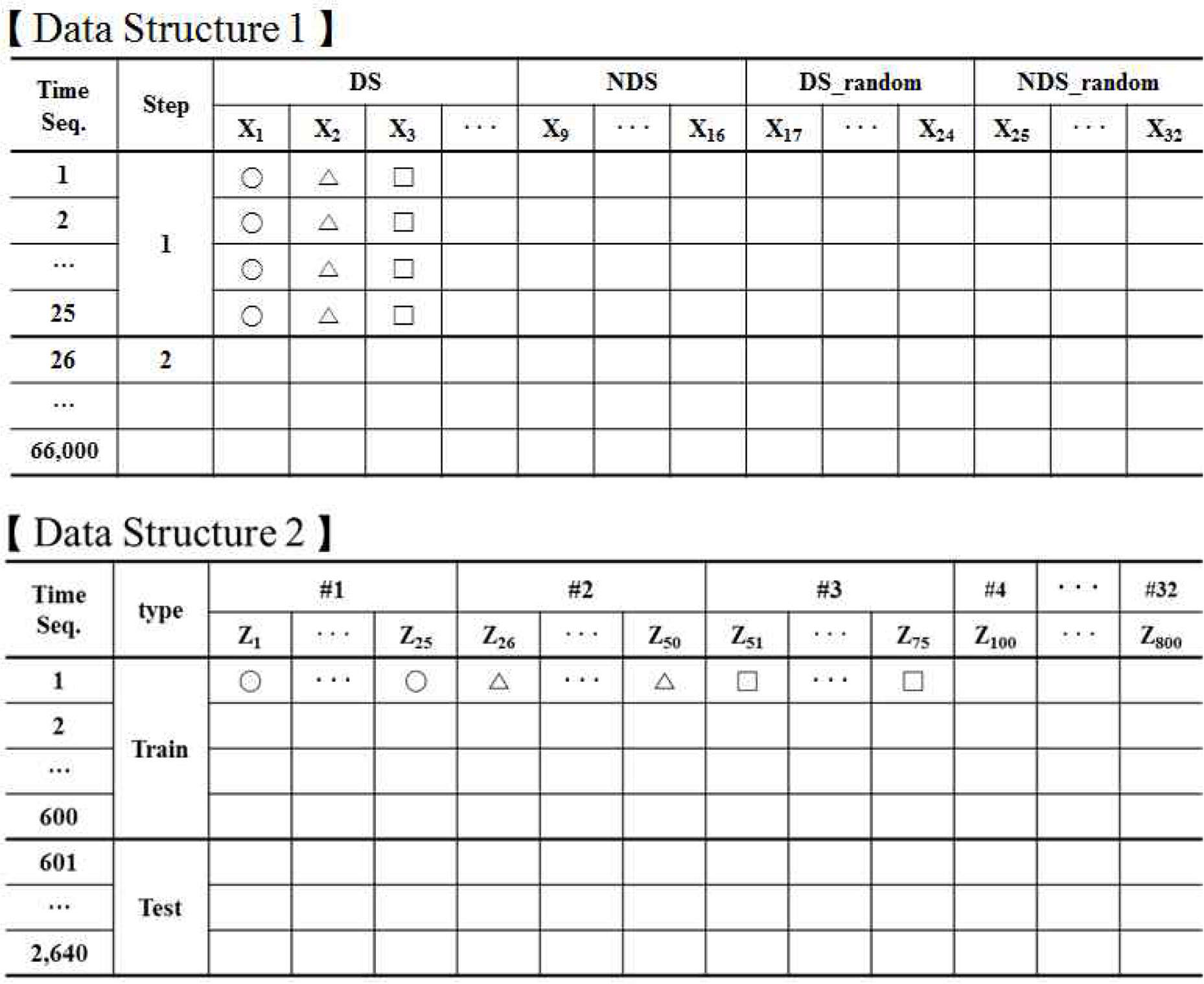
이러한 원천데이터에 대해 진동의 변화를 직관적으로 쉽게 파악할 수 있는 시간영역 통계적 특징을 추출(feature extraction) 하였다. 시간영역 통계적 특성으로 평균, 제곱평균제곱근(root mean square), 왜도, 첨도, 최대, 최소, PTP(peak to peak), Crest factor 8개를 사용하였다. <Figure 4>에서는 다양하게 추출된 데이터 특징들 사이의 관계를 산점도로 나타내었다. 추출된 변수사이에는 0.96의 높은 상관관계를 가지는 특징부터 0에 가까운 낮은 상관관계를 가지는 것까지 다양하게 나타났다. 특히, 시계열 특성을 갖는 데이터에서 구간별로 레이블을 부여하고 산점도에 색을 넣어 표현한 결과 초기데이터의 구간이 시간이 흐름에 따라 보라색에서 빨간색 방향으로 데이터가 이동하고 있는 것을 볼 수 있는데 이것을 통해 평가하고자 하는 데이터가 시간에 따라 상태가 특정 방향으로 변화하고 있음을 직관적으로 확인 할 수 있다. 데이터는 구동(drive), 비구동(non-drive) 두 곳에서 수집되었고, 8개의 통계적 특징을 추출하여 16개의 변수를 얻었다. 시계열데이터는 추세변동(trend movement), 주기변동(cyclic fluctuation), 불규칙변동(random movement)으로 분리할 수 있다. <Figure 5>의 위쪽과 같이 얻어진 16개의 변수에서 추세변동과 주기변동을 제거한 무작위(random) 변동요소만을 별도로 16개의 변수를 추출하여 총 32개의 변수 하나당 66,000개를 확보하였다. 이를 흑백이미지을 이용하여 변화를 직관적으로 확인하기 위해 식(1)을 이용하여 모든 데이터를 0~255 사이 값으로 표준화하였다. 여기서 얻어진 데이터 25개 행을 한 묶음으로 32개를 묶어 800개의 열로 만들면 데이터의 개수는 2,640개가 얻어지고 분석에 사용한 데이터 구조는 <Figure 5>의 아래 그림과 같다. 시계열 앞쪽 600개를 훈련데이터로 오토인코더를 학습시키고 나머지를 검증데이터로 데이터의 변동을 확인하고자 한다.
4. 오토인코더를 이용한 설비상태 진단모형
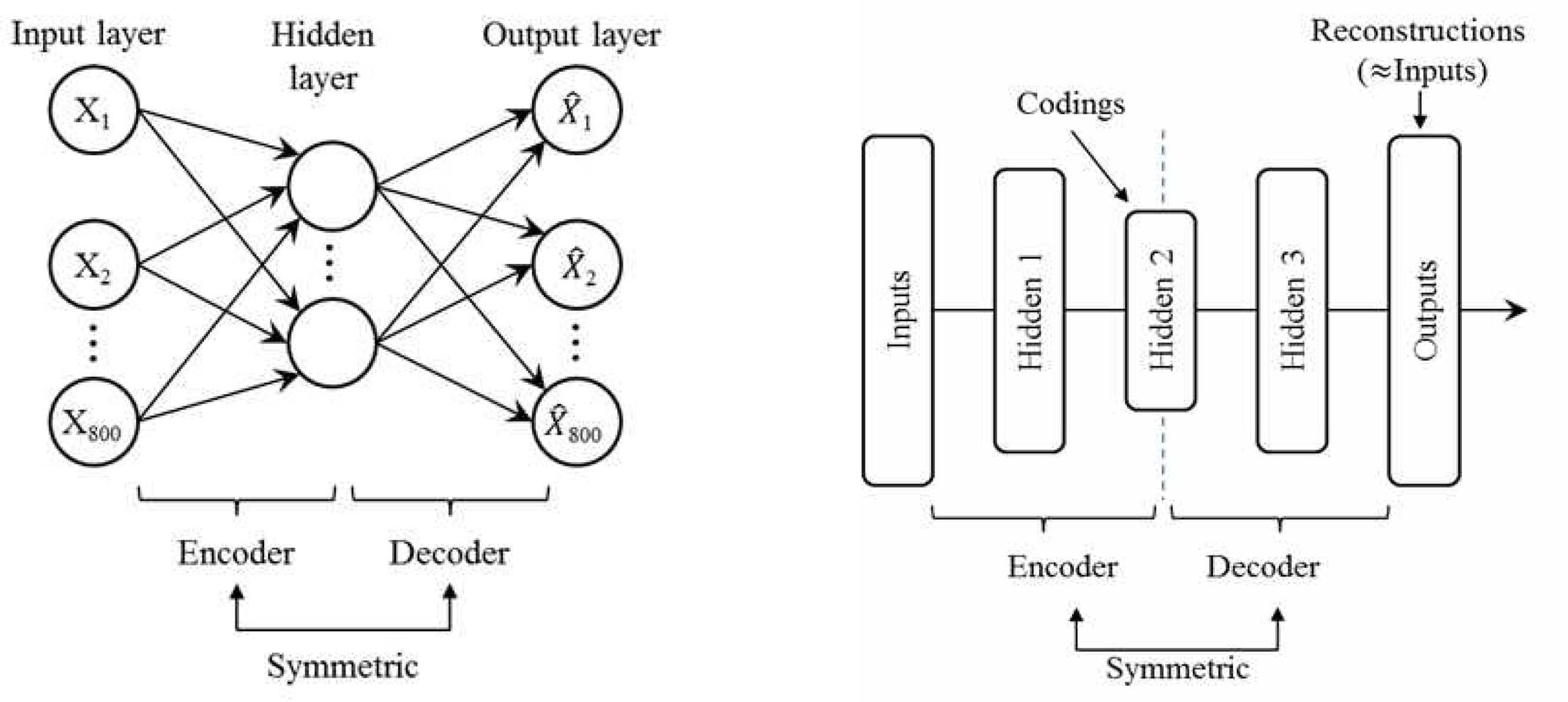
오토인코더는 <Figure 6>의 그림과 같이 단순히 입력을 출력으로 재생성하는 인공신경망으로 구조가 간단하여 계산부하가 상대적으로 작고, 레이블이 없는 설비진단 및 모니터링을 위한 비지도학습에 사용할 수 있는 딥러닝 알고리즘이다. 레이블이 없는 학습데이터임에도 불구하고 입력과 입력을 재생성한 결과를 비교하여 성능을 오차로 정량적으로 표현할 수 있는 장점이 있어 본 논문의 진단 알고리즘으로 채택하였다. 오토인코더는 입력과 출력의 차인 재구성오차(reconstruction error)를 최소화하는 방향으로 학습하는데, 재구성오차란 이상치 점수(anomaly score)라고도 불리며 입력과 출력간에 측정된 오차의 크기로 식 (2)와 같이 정의된다. 단일층(single layer) 오토인코더는 하나의 은닉층(hidden layer)이 있는 앞먹임(feedforward) 인공신경망이다. 오토인코더에서의 병목층(bottleneck layer)은 차원축소(dimension reduction) 또는 데이터 압축을 위해 사용되며, 병목층에서 의미있는 표현(representation)을 얻기 위해 입력층의 크기보다 적은 병목층을 설계한다. 이러한 병목층의 설계는 오토인코더가 단순히 입력을 바로 출력으로 복사하지 못하도록 하며, 데이터를 효율적으로 표현하도록 학습을 조절한다. 즉, 오토인코더는 저차원을 가지는 은닉층에 의해 입력을 그대로 출력으로 복사할 수 없으므로 출력이 입력과 같아지도록 입력데이터의 가장 중요한 특징을 학습하도록 만든다. 이렇게 입력 데이터의 특징을 학습한 모델에서 생성되는 재구성오차를 이용하여 데이터의 이상을 발견할 수 있다. <Figure 6>의 오른쪽은 단일층 오토인코더와 적층오토인코더(stacked autoencoder)의 구조를 보여주고 있다. 적층오토인코더는 2개 이상의 은닉층을 가지며 층을 추가할수록 더 복잡한 부호화를 실행 할 수 있다고 알려져 있다. 입력 x∈Rn이 주어지면, 오토인코더는 은닉층의 표현 f∈Rm을 통해 출력 y∈Rm을 계산한다. 은닉층의 활성화는 y=g(w2f(x)+b2)과 f(x) = g(w1x1 +b1) 및 출력층에 따라 결정된다. W1∈Rm×n 과 W2∈Rm×n은 가중치 행렬(weight matrix)이고, b1∈Rm 과 b2∈Rn은 바이어스 벡터(bias vector)이며 g(z)=1/(1+exp(-z))는 벡터 z에 성분별로 적용되는 활성화 함수(activation function)이다. 오토인코더는 훈련데이터에 대해 y≈x가 되도록 경사하강법(gradient descent method)을 사용하여 W1, W2, b1 및 b2을 구하기 위해 오류역전파알고리즘(error back propagation algorithm)을 적용한다. 오토인코더의 학습은 이러한 매개변수집합을 최적화하기 위한 것이다. 평균제곱오차(mean square error, MSE)는 대표적인 오토인코더 손실함수(loss function)로 사용되며 식 (2)과 같이 정의된다.
일반적으로 인공신경망은 과적합(over fitting) 문제를 안고 있다. 이를 해결하기 위해 여러 가지 기법이 사용되는데 그 중에 드롭아웃(dropout)기법은 신경망 전체를 학습하지 않고 일부 노드만 무작위로 골라 학습하는 방법으로 구현은 복잡하지 않으면서 효과는 뛰어나다. 본 논문에서는 직관적으로 이해하기 쉬운 시계열 데이터의 시간영역 특징(time domain feature)을 생성하고 이것을 입력데이터로 사용한다. 오토인코더를 이용하여 정상상태의 설비데이터의 시간영역 특징을 학습하여 모델을 생성시킨다. 이 모델은 정상상태의 설비데이터가 입력될 경우 작은 재구성오차를 보이며, 현재 상태와 다른 상태 즉, 지금까지 학습하지 못한 설비데이터가 입력될 경우 큰 재구성오차를 보일 것이다. 본 논문에서는 재구성오차는 망소특성을 가지지만 기존 모델의 3시그마(3σ)를 초과하는 경우 정상상태와는 다른 상태로 전이했다고 판단한다. 하지만, 비지도학습에 사용된 데이터의 특성상 레이블이 없으므로 전이된 다른 상태가 설비이상이라고 단정할 수 없다. 재구성오차가 임계값을 넘는 경우 알람을 제공하고, 소수리, 중수리 등 정기수리시 설비점검을 통해 어떤 기계적, 전기적 고장이 발생했는지에 대한 실무적인 판단이 필요하다.
5. 실험 및 고찰
오토인코더의 구조는 단순하지만 은닉층의 수, 은닉층 노드수, 드롭아웃 비율, 학습률(learning rate) 등과 같이 다양한 초모수(hyper-parameter)를 통해 성능을 향상시킬 수 있다. 본 논문에서 설비이상 탐지를 위해 사용된 초모수를 <Table 1>에 나타내었다. 모델은 단일층 오토인코더의 은닉층의 수를 100, 200, 400로 증가시키면서 활성화 함수가 하이퍼볼릭탄젠트(tanh)와 ReLU(rectifier linear unit)인 경우, 드롭아웃비율이 0, 0.2, 0.5인 경우로 설계하였다. MSE(mean square error), RMSE(root mean square error)를 모델간 성능비교 기준으로 하였다. <Table 1>에서 보는 바와 같이 은닉층의 노드수가 400개, 활성화 함수는 하이퍼볼릭탄젠트, 드롭아웃비율을 0.2일 때 MSE와 RMSE가 각각 0.0549, 0.2344로 모델중 최소값을 보여 가장 성능이 우수한 모델이었다. 입력층이 800개인데 100과 200개로 은닉층을 작게 설계할 경우 제대로 데이터 형상을 추출하지 못한 것으로 판단된다. 활성화함수로 ReLU를 사용한 경우 함수의 단순성으로 인해 계산시간은 감소하지만 하이퍼볼릭탄젠트에 비해 MSE와 RMSE 기준 성능은 열위하였다. 가운데 은닉층 노드수를 400개로 고정하고 은닉층 노드수 500, 600, 700개를 추가하여 적층오토인코더를 <Table 2>과 같이 설계하여 모델간 성능을 비교하였으나 성능은 단일층 오토인코더에 비해 우수하지 못했다. 적층오토인코더의 성능이 좋지 않은 것은 원천데이터 자체의 복잡성이 높지 않아 단일층 오토인코더로도 데이터의 특징 잘 추출되었거나, 본 논문의 훈련에서 사용된 입력 데이터셋 수가 제한적이어서 학습을 제대로 수행하지 못했을 것으로 판단된다.
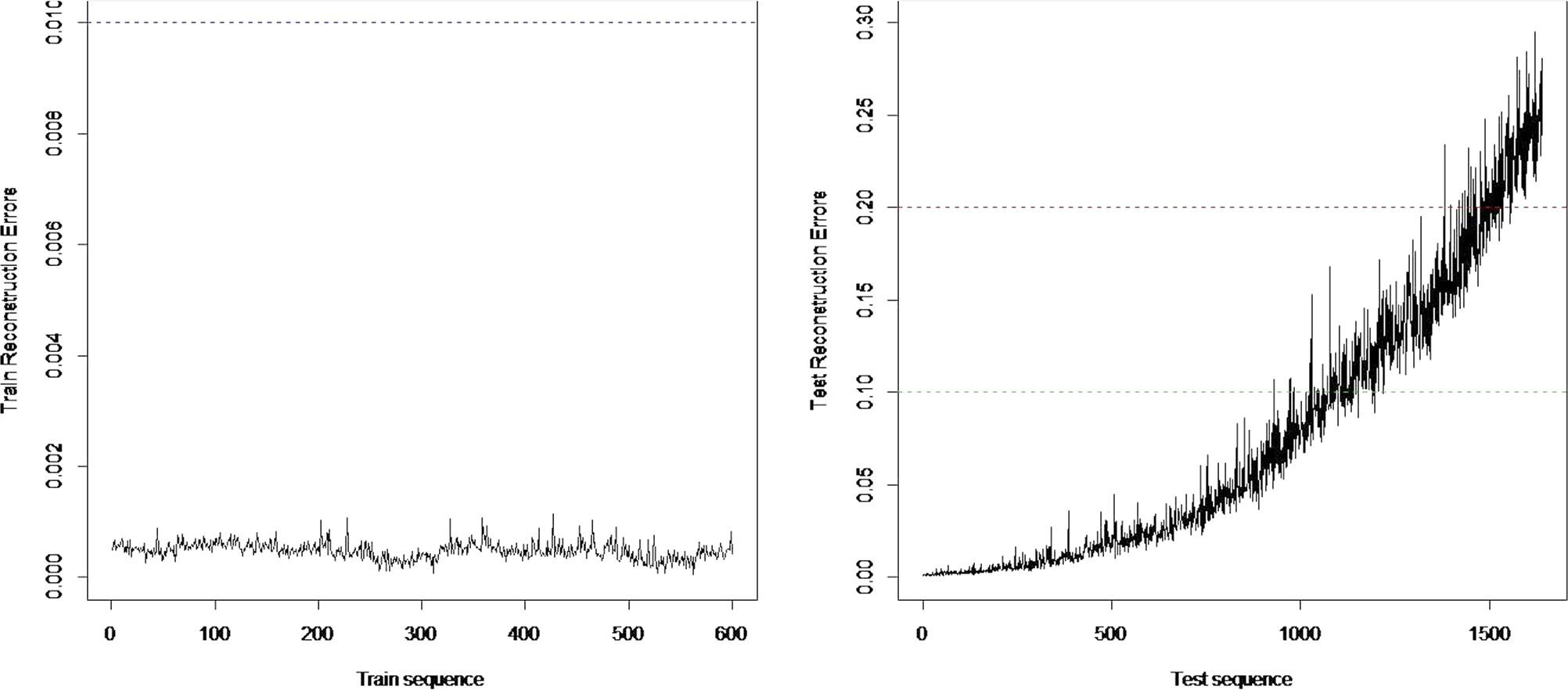
<Table 1>에서 성능이 가장 우수한 모델 14번을 기준모델에 검증데이터를 입력하여 재구성오차의 변화를 관찰하였다. <Figure 7>의 왼쪽 그래프는 훈련데이터를 이용한 오토인코더 모델의 재구성오차이며, 모델에서 학습하여 기준이 되는 평균 재구성오차가 0.001이하, 표준편차(1σ)는 0.015 수준으로 유지되고 있으나 검증데이터의 경우 마지막 구간에서 재구성오차가 0.29까지 지수적으로 증가하는 것을 볼 수 있다. <Figure 8>은 검증데이터의 구간별 재구성오차의 추세를 나타내고 있다. 검증데이터의 시간순서상 시작구간인 1~100에서 재구성오차의 평균은 0.004로 훈련데이터를 이용한 모델 재구성오차의 4배 수준을 보였다. 중간 구간인 1001~1100에서는 0.029, 마지막 구간인 1901~2000에서는 0.198로 마지막구간은 시작구간의 52.3배, 중간구간의 6.8배로 매우 크게 나타났다. 이것은 더 이상 기준모델을 통해 입력을 출력으로 생성했을 때 재구성오차가 크며, 훈련데이터에서 학습한 유형의 데이터와 다른 데이터가 입력되었음을 나타낸다. 이를 통해 우리는 설비의 상태가 과거와 달라졌음을 알 수 있고, 알람을 통해 설비점검을 위한 정보를 제공할 수 있다.
<Figure 9>는 각 시점 별로 흑백의 이미지로 변환한 입력이미지(original image)와 출력(reconstruction image)을 비교하고 있다. <Figure 9(a)>의 입력 이미지는 오토인코더를 통해 <Figure 9(d)>로 유사하게 재구성됨을 볼 수 있다. 하지만, <Figure 9(c)>의 입력 이미지는 오토인코더를 통해 <Figure 9(f)>로 재구성될 때 이미지가 흐려지고, 제대로 원본 이미지를 재구성하지 못하는 것을 확인 할 수 있는데 이것은 원래의 이미지를 재구성할 때 재구성오차가 크게 발생한 결과임을 이미지를 통해 직관적으로 이해할 수 있다. 또한, 설비이상의 레이블을 얻을 수 있는 경우 시계열 데이터를 이미지로 만들고 이것을 입력 이미지로하는 합성곱신경망(convolutional neural network, CNN)를 활용하여 설비상태의 변화를 판단하고 이상여부를 분류할 수 있을 것이다.
6. 결론
본 연구에서는 오토인코더를 기반으로 설비이상을 진단하는 알고리즘의 사례연구를 수행하였다. 오토인코더의 특징인 재구성오차를 이용하여 설비의 상태변화를 탐지할 수 있음을 보였다. 단일층 오토인코더와 적층오토인코더를 비교하고, 과적합을 방지하기 위해 다양한 드롭아웃 비율을 적용하였다. 실험결과 적층오토인코더 보다 단일층 오토인코더가 우수한 성능을 보였다. 이는 데이터 자체가 가지는 복잡성이 적어 단일층 오토인코더로도 충분히 데이터의 특징을 잘 추출되었거나, 입력 데이터셋의 개수가 충분히 많지 않아 제대로 학습을 수행하지 못했을 수 있다고 판단되며 이후 보다 많은 데이터 수집을 통해 극복해야할 것으로 보인다. 정상상태로 판단되는 구간의 데이터를 이용하여 재구성오차가 0.001이하가 되도록 모델을 설정하고, 검증데이터를 통해 재구성오차를 관찰한 결과 시간이 지남에 따라 재구성오차가 시작구간 대비 52.3배까지 증가하는 것을 확인하였다. 이를 통해 재구성오차가 정상으로 판단되는 시점대비 3시그마를 초과하는 시점에 경고를 발생시켜 비계획 정지를 예방할 수 있음을 보였다. 재현성이 높고 정확한 결과를 얻기 위해서는 지금보다 학습데이터의 양을 늘려 모델을 안정화하여 비교할 필요가 있다. 본 연구에서 초점을 둔 고장진단의 경우 설비의 성능저하가 어느 정도 진행되었을 때 재구성오차기 크게 나타나게 되므로 현장에서 사용되기에는 효용성의 한계가 있다. 이를 보완하기 위한 연구로 재구성오차의 시계열 특성을 반영하여 잔여수명(remaining useful life, RUL)을 예측하는 방향으로 연구가 이루어져야 할 것이다. 또한, 향후 합성곱인공신경망(CNN)과 같은 이미지 분류에 좋은 성능을 보이는 인공지능 알고리즘을 이용해 설비이상을 판단하고 기존 모델과 성능을 비교-평가하는 연구가 필요하다. 마지막으로 데이터를 기반한 설비 이상진단의 경우 신뢰할 수 있는 정상데이터를 얻는 것이 중요하므로 설비보전 전략에 있어 설비를 설치한 초기에 최대한 많은 정상데이터를 취득하는 과정이 고려되어야 할 것이다.