XAI(eXplainable Artificial Intelligence) 알고리즘 기반 사출 공정 수율 개선 방법론
Injection Process Yield Improvement Methodology Based on eXplainable Artificial Intelligence (XAI) Algorithm
Article information
Trans Abstract
Purpose
The purpose of this study is to propose an optimization process to improve product yield in the process using process data. Recently, research for low-cost and high-efficiency production in the manufacturing process using machine learning or deep learning has continued. Therefore, this study derives major variables that affect product defects in the manufacturing process using eXplainable Artificial Intelligence(XAI) method. After that, the optimal range of the variables is presented to propose a methodology for improving product yield.
Methods
This study is conducted using the injection molding machine AI dataset released on the Korea AI Manufacturing Platform(KAMP) organized by KAIST. Using the XAI-based SHAP method, major variables affecting product defects are extracted from each process data. XGBoost and LightGBM were used as learning algorithms, 5-6 variables are extracted as the main process variables for the injection process. Subsequently, the optimal control range of each process variable is presented using the ICE method. Finally, the product yield improvement methodology of this study is proposed through a validation process using Test Data.
Results
The results of this study are as follows. In the injection process data, it was confirmed that XGBoost had an improvement defect rate of 0.21% and LightGBM had an improvement defect rate of 0.29%, which were improved by 0.79%p and 0.71%p, respectively, compared to the existing defect rate of 1.00%.
Conclusion
This study is a case study. A research methodology was proposed in the injection process, and it was confirmed that the product yield was improved through verification.
1. 서 론
사출 공정은 자동차, 디스플레이, 반도체 산업 등의 핵심 부품과 주변 부품을 대량 생산할 수 있는 효과적인 제조 공정 기법으로 여러 제조 산업의 중요한 기반이 된다(Zhao et al., 2014). 사출 공정에서 높은 수율을 유지하기 위해 서는 사출 속도, 수지 온도, 보압 시간 등 여러 변수의 최적 관리가 필요하다(Kim et al., 2001).
본 연구에서는 설명 가능한 인공지능 기법(eXplainable Artificial Intelligence; XAI) 기반 SHAP(SHapley Additive exPlanations) 기법을 이용하여 공정에서 불량 여부를 결정하는 데에 영향을 미치는 주요 변수들을 추출한다. 변수 추출을 위해 트리 기반 알고리즘인 XGBoost와 LightGBM을 사용하였다. 이후 ICE(Individual Conditional Expectation) 기법을 이용하여 추출된 변수들의 통제 범위를 제시하고 Test Data로 유효성 검증을 거친 후 사출 공정 불량률 개선을 위한 방법론을 제안하고자 한다.
2. 이론적 배경 및 선행연구
2.1 사출 성형 공정
사출 성형은 Figure 1(Korea AI Manufacturing Platform(KAMP), 2020)과 같이 플라스틱 성형법 중 하나로 용해된 열가소성 수지를 금형 안에 주입한 뒤 냉각시키는 과정을 통해 진행된다(Chung and Kim, 2008). 성형 사이클이 짧고 대량 생산이 가능해 최근 반도체, 자동차 등 다양한 산업 분야에서 활용되고 있다. 이러한 사출 성형 공정을 통해 생산된 제품들은 완제품의 마감재이기에, 반드시 고품질을 유지해야 한다. 이에 제품의 품질을 결정하는 주요 변수인 수지의 온도, 압력 등을 적절히 통제하는 것은 공정 전반의 수율에 있어서 매우 중요하다(Thiriez and Gutowski, 2006).
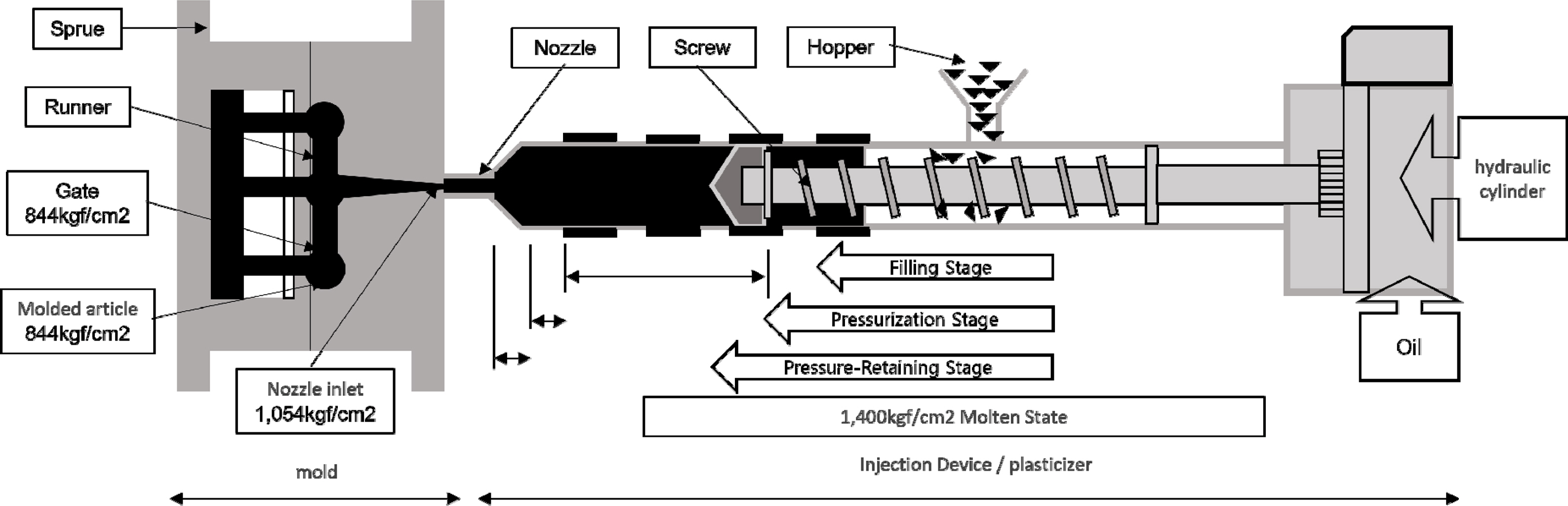
Principle of Injection Molding
2.2 XAI(eXplainable Artificial Intelligence)
사출 공정은 대표적인 제조공정 중 하나로 이미 높은 수율을 보인다. 보다 높은 수율 확보를 위해서 최근 공정데이터를 활용한 여러 인공지능 기반 공정개선 프로세스가 연구되고 있다(Hwang et al., 2021; Yang et al., 2020). 본 연구에서는 XAI 기법을 활용하여 공정개선 방안을 제시하고자 한다. XAI는 기존 블랙박스 특징을 가지는 기계학습과는 달리 기계학습의 결정에 대한 근거 및 타당성을 제시하며 신뢰도를 높이는 기법이다(Arrieta et al., 2020). 이를 활용해 공정의 불량률 감소를 위한 구체적인 근거를 제시한다.
Oh 등은 2021년의 연구 “SHAP를 활용한 산업재해 예측 모델링 및 분석”에서 산업안전보건 실태조사 데이터를 기반으로 산업재해에 주요한 영향을 미치는 요인을 분석하였다(Oh et al., 2021). 상시 근로자의 수, 업무 교대 근로자 비율 등의 영향을 분석하였다.
XAI에는 LIME, SHAP, ICE, PDP 등 여러 가지 기법이 존재한다(An and Jo, 2021). 본 연구에서는 XAI 기법 중 SHAP와 ICE 기법을 적용하여 공정의 주요 변수를 추출하고 해당 변수의 변화에 따른 사출 공정에서의 불량 여부를 확인하고자 한다. SHAP 기법은 종속 변수에 대한 독립 변수 x들의 기여도를 산출하는 이론이다. 각 변수에 대한 중요도를 계산하기 위해 여러 변수들의 조합을 구성하여 해당 변수의 유무에 따른 변화를 통해 기여도를 도출한다. ICE 기법은 각 인스턴스에 대한 예측 의존도를 시각화하여, 인스턴스 별로 선 그래프를 그린다. 이를 통해 개별 관측의 수준까지 상세히 탐색할 수 있으며 변수별 최적의 공정 조건을 제시할 수 있다.
3. 방법론
이번 장에서는 본 논문에서 제안하는 주요 공정변수 추출 및 최적 공정변수 범위 산출과정을 설명한다. 해당 과정은 Figure 2에 기술되었듯이 총 4단계로 구성된다.
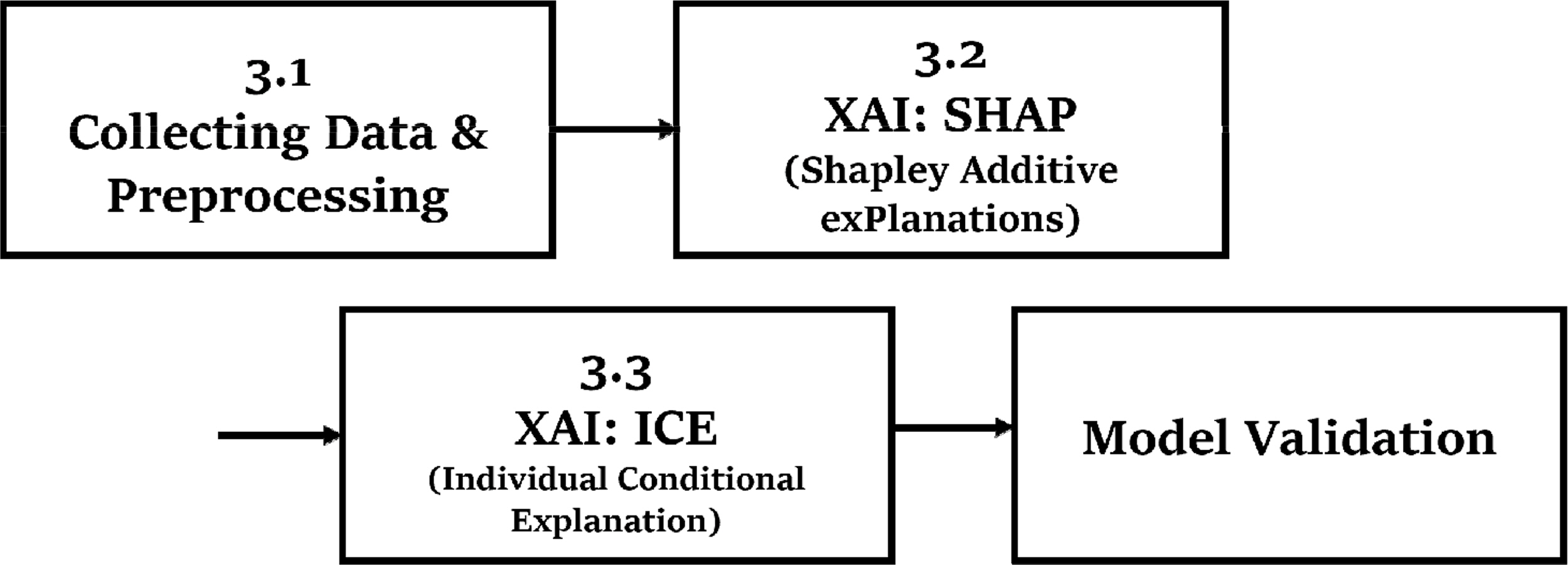
Methodology Process
3.1 데이터 수집 및 전처리
본 논문은 KAIST에서 제공하는 인공지능 중소벤처 제조 플랫폼(KAMP)의 사출성형기 AI 데이터셋을 사용한다(Korea AI Manufacturing Platform(KAMP), 2020). 전처리 과정으로써 데이터셋 전체에 걸쳐 같은 값을 가지는 변수는 학습에 유의미하지 않으므로 삭제한다. 추가로 Injection_Time과 같이 수지의 온도나 스크류의 압력 등 다른 변수의 영향을 받는 변수는 실험에 고려하지 않는다. 마지막으로 다른 제품을 생산한 데이터에 해당하는 극소수의 행을 삭제한다. 이후 학습을 위해 Train Data와 Test Data를 5:5 비율로 나누어 실험을 진행한다. 사출 공정은 이미 높은 수율을 보이기에, 정상 데이터에 비해 불량 데이터가 극도로 부족하다. 본 논문에서 사용한 데이터 역시 정상 데이터에 비해 불량 데이터가 적은 불균형한 분포를 가진다. 이는 모델의 학습 과정에서 편향된 결과로 이어질 수 있기에 오버샘플링을 진행한다(Mohammed et al., 2020). 오버샘플링은 낮은 비율의 데이터의 수를 늘리는 기법으로 본 논문에서는 SMOTE(Synthetic Minority Over-sampling TechniquE) 알고리즘을 통해 Figure 3과 같이 오버 샘플링을 진행한다.
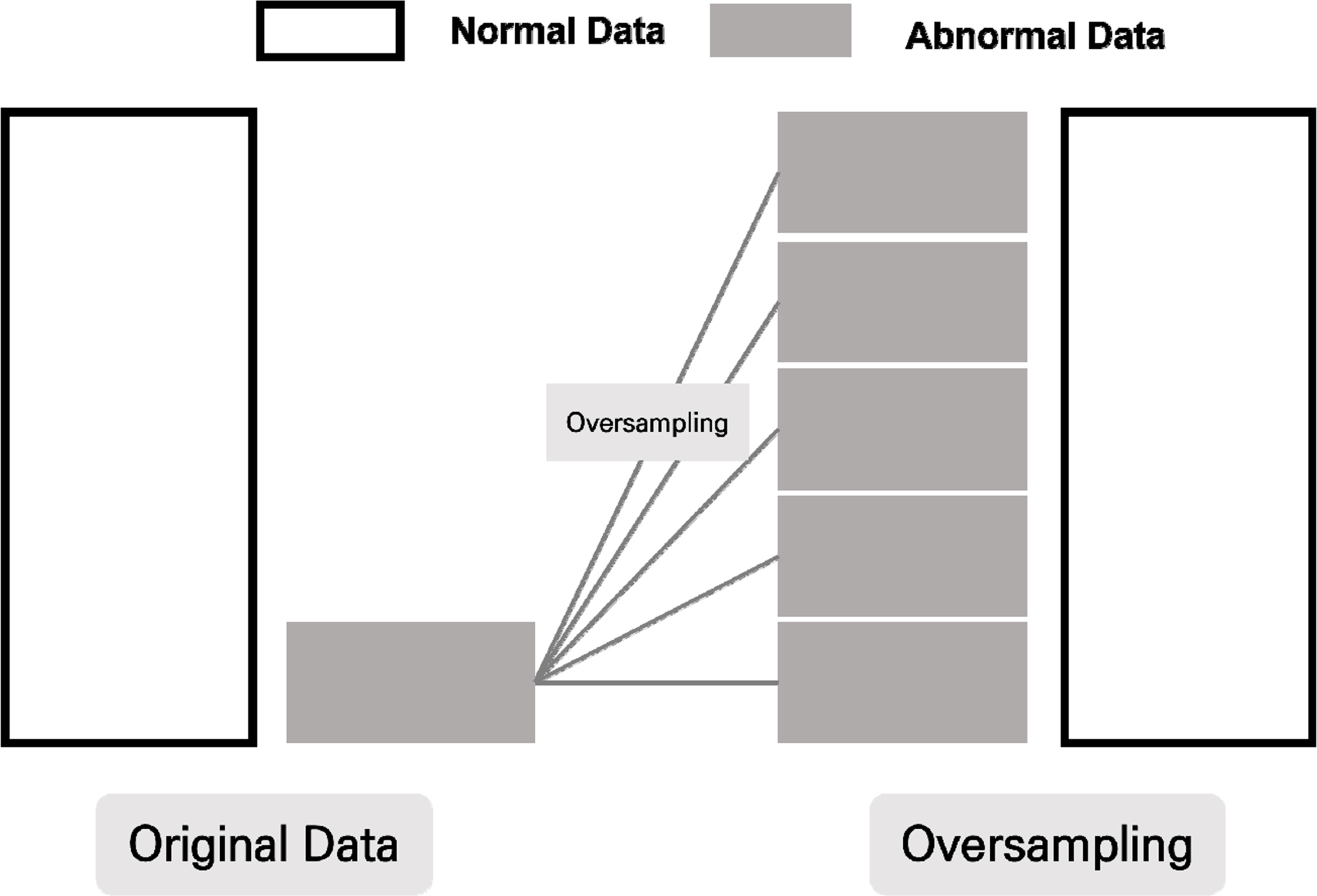
Oversampling
SMOTE 알고리즘은 기존 데이터를 단순복제하는 것이 아닌 K개의 최근방 관측치에 가중치를 두어 새로운 인공적인 관측치를 생성하는 기법이다(Lee et al., 2021). 새로운 관측치의 생성 과정은 수식 (1)을 통해서 진행된다. 이때 x는 최초에 선택된 관측치를, xj는 x 근방의 관측치를 나타내며, ω는 0과 1 사이의 값을 갖는 가중치를 의미한다.
3.2 SHAP(SHapley Additive exPlanations)
XAI 기법 중 하나인 SHAP는 로이드 섀플리(Lioyd Stowell Shapley)가 만든 게임 이론의 Shapley Value를 기반으로 한다(Lundberg and Lee, 2017). Shapley Value란 모델에 영향을 미치는 독립 변수의 중요도를 확인하기 위한 지표로써, 해당 모델을 구성하는 여러 독립 변수들의 조합을 기반으로, 변수 채택의 유무에 따른 종속 변수의 평균적 변화를 바탕으로 계산된다(Lee et al., 2022). SHAP 기법은 독립 변수 간 의존성과 음의 영향력을 고려할 수 있어서 정확한 영향력 계산이 가능하다. 계산 과정은 수식(2)와 같이 표현 가능하며, 이를 통해 모델의 종속 변수인 불량 여부에 대한 특정 독립 변수의 공헌도를 설명할 수 있다. 이때, g는 설명 모델, z′는 변수, M은 변수의 개수이며, ϕj는 변수 j의 기여도를 의미한다.
본 연구에서는 공정의 불량률 개선을 위한 주요 변수 도출 과정에서 SHAP 기법을 사용한다. 학습에는 부스팅 기반 알고리즘인 XGBoost(Chen and Guestrin, 2016)와 LightGBM을 사용한다(Ke et al., 2017). XGBoost와 LightGBM 모두 Decision Tree 기반 모델로써, 병렬 학습이 가능해 연산속도가 빠르다는 장점을 가진다(Lee et al., 2021). 빠른 속도로 진행되는 사출 공정의 특징상 공정의 실시간 관리를 가능하게 하기 위해 해당 모델을 사용하였다. 이후 Shapley Value의 평균을 나타내는 그래프를 그리고, 이를 바탕으로 공정의 주요 변수를 추출한다.
3.3 ICE(Individual Conditional Expectation)
ICE는 특성이 변화할 때 인스턴스 별 예측치의 변화를 나타내는 그래프이다(Goldstein et al., 2015). 다른 독립 변수들은 통제한 상태로 각각의 인스턴스마다 SHAP 기법을 통해 얻은 주요 변수의 변화에 따른 종속 변수의 예측치 변화 추이를 선으로 시각화한다. 이때 독립 변수의 범위는 데이터에 근거하여 ICE 기법이 결정한다.
PDP(Partial Dependence Plot)는 ICE Plot의 평균을 취한 하나의 선으로, N번 반복한 인스턴스들의 평균 효과를 나타낸다(Wu et al., 2021). PDP를 통해 모든 인스턴스를 대표하는 그래프를 도출할 수 있으며, 이는 직관적이고 명확하여 해석이 용이하다.
본 연구에서는 SHAP를 통해 산출한 주요 변수들의 변화에 따른 종속 변수인 불량 확률의 변화 추이를 나타내고, 이를 평균화한 PDP를 통해 각 변수에 대한 통제 범위를 제시한다.
이후 실험 이전 나눈 Test Data로 공정의 주요 변수 및 통제 범위 선정의 유효성 검증 과정을 거치며 공정개선 여부를 확인한다.
4. 실험 및 실험 결과
본 논문에서는 XGBoost와 LightGBM의 결과 비교를 위해 각각 실험을 수행하여 결과를 제시한다. Figure 4는 본 연구의 전체적인 과정을 보여주는 순서도이다.

Summary of Experimental Process
4.1 데이터 수집 및 전처리
본 논문에서 사용하는 자동차 앞 유리 사이드 몰딩 사출성형기 AI 데이터셋은 인덱스 변수인 ‘_id’, ‘TimeStamp’와 종속 변수인 ‘PassOrFail’을 제외하고 25개의 변수를 가진다(KAMP, 2020). 그 중 ‘Injection_Time’과 같이 공정 불량 예측에 영향을 끼치지 않거나 이미 잘 통제되어 데이터셋 전체에 걸쳐 같은 값을 가지는 변수들은 삭제하여 16개의 변수만을 고려한다. 또한, 생산 제품 차이로 인한 영향을 배제하기 위하여 다른 제품 생산 데이터에 해당하는 4개의 행을 제외한 7,919행의 데이터를 사용한다. 데이터 프레임의 예시와 사용한 변수의 목록은 Figure 5와 같으며 변수에 대한 설명은 Table 1과 같다.
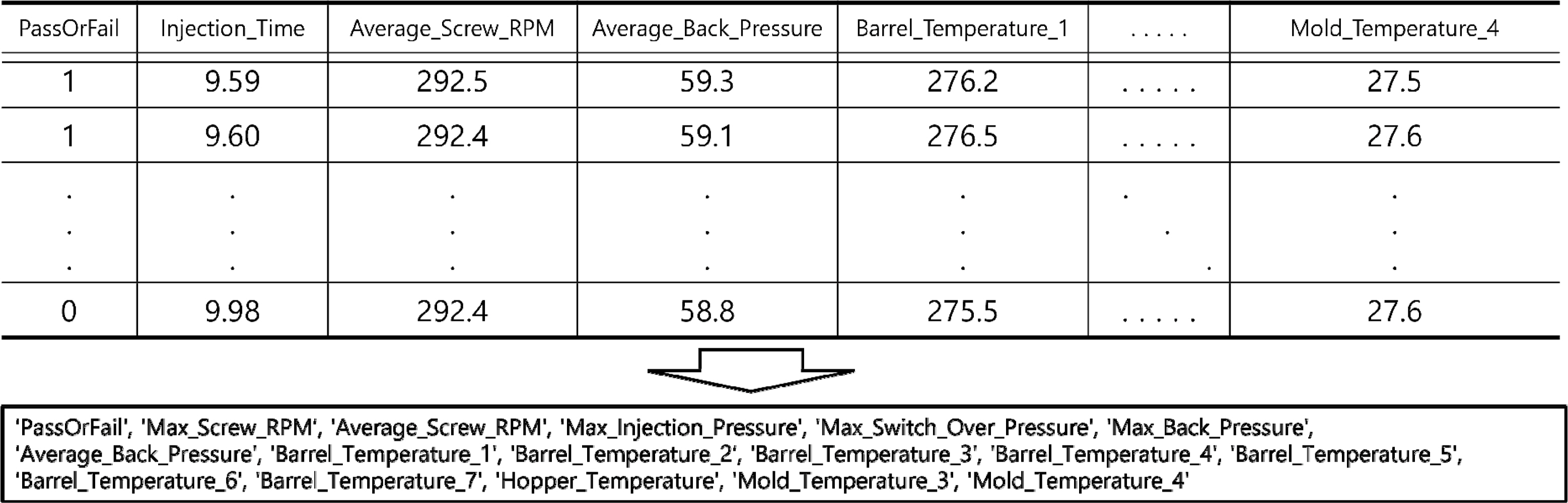
Example Dataframe & Used Feature
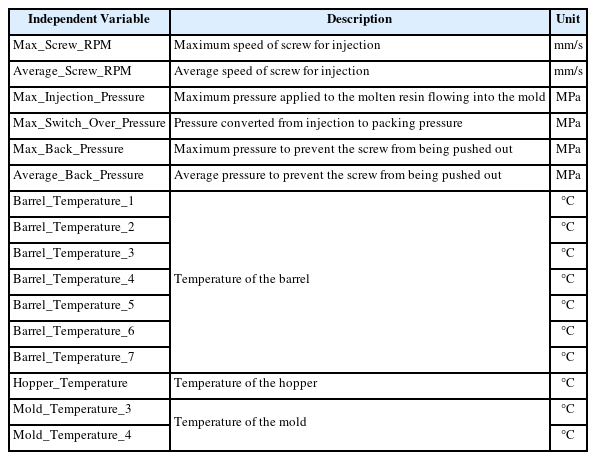
Description of Independent Variables
본 연구에서 사용한 데이터는 정상 7,848개, 불량 71개이며, 이를 Train Data와 Test Data를 5:5 비율로 나누어 실험을 진행한다. 학습에 사용될 Train Data의 경우 정상 3,964개, 불량 31개로 구성되며, 검증에 사용될 Test Data의 경우 정상 3,955개, 불량 40개로 약 1.0%의 불량률을 가진다. 본 데이터와 같이 불균형한 데이터로 분석을 진행할 시 편향된 학습으로 이어져 모델 전체의 성능을 저하시킨다. 이를 해결하기 위해 SMOTE 알고리즘을 이용하여 오버샘플링을 진행한다. 오버샘플링을 진행할 시에 고려한 최근방 관측치의 개수를 나타내는 K의 값은 5로 설정하였으며, 해당 수치는 SMOTE 알고리즘의 Default 값으로써 사용하였다. 불량 데이터를 정상 데이터의 개수와 같은 수치인 3,964개로 증가시켜 최종적으로 완성된 Train Data는 총 7,928개이다.
4.2 SHAP(SHapley Additive exPlanations)
XGBoost와 LightGBM을 사용하여 각 변수의 Shapley Value의 평균값을 나타낸 그래프는 Figure 6과 같다. 그래프상에서 확인할 수 있듯, XGBoost의 경우 상위 6개의 변수가, LightGBM의 경우 상위 5개의 변수가 전체 중요도의 약 70%에 해당하므로 주요 변수로 선정하였고, Table 2와 같다. 두 모델 모두에서 유사한 변수들이 주요 변수로 선정되었으며, 한 모델에서만 선정된 주요 변수의 경우에도, 나머지 모델에서 비교적 높은 중요도를 보임을 확인할 수 있다.

Result of SHAP

Result of SHAP Method
4.3 ICE(Individual Conditional Expectation)
Table 1에서 확인한 모델별 주요 변수들에 대한 ICE Plot을 확인한다. XGBoost와 LightGBM으로 학습한 주요 변수들의 ICE Plot은 각각 Figure 7, Figure 8과 같다. 모든 인스턴스의 평균값에 해당하는 PDP는 Figure 상에 황색 선으로 나타내었다. ICE Plot에서 Y값이 커질수록 제품이 양품일 가능성이 큰 것을 뜻하며, 이를 통해 각 변수의 통제 범위를 선정한다. XGBoost를 통해 추출한 주요 변수 중 Average_Back_Pressure(Figure 7. a)를 예시로 들어보면, 59.0부터 65.7 사이를 연속적으로 변화시켜 가면서 양품일 확률을 예측한다. 그 결과 59.0과 60.1 사이일 때, 63.0과 65.7 사이일 때 양품일 확률이 높다.
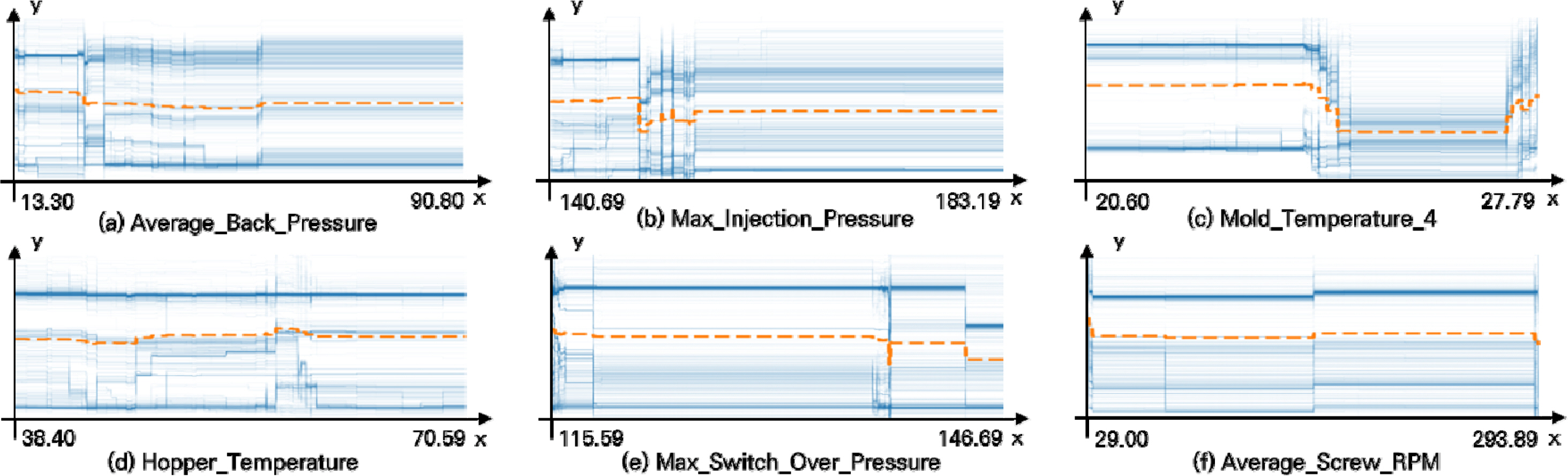
ICE Plot of XGBoost
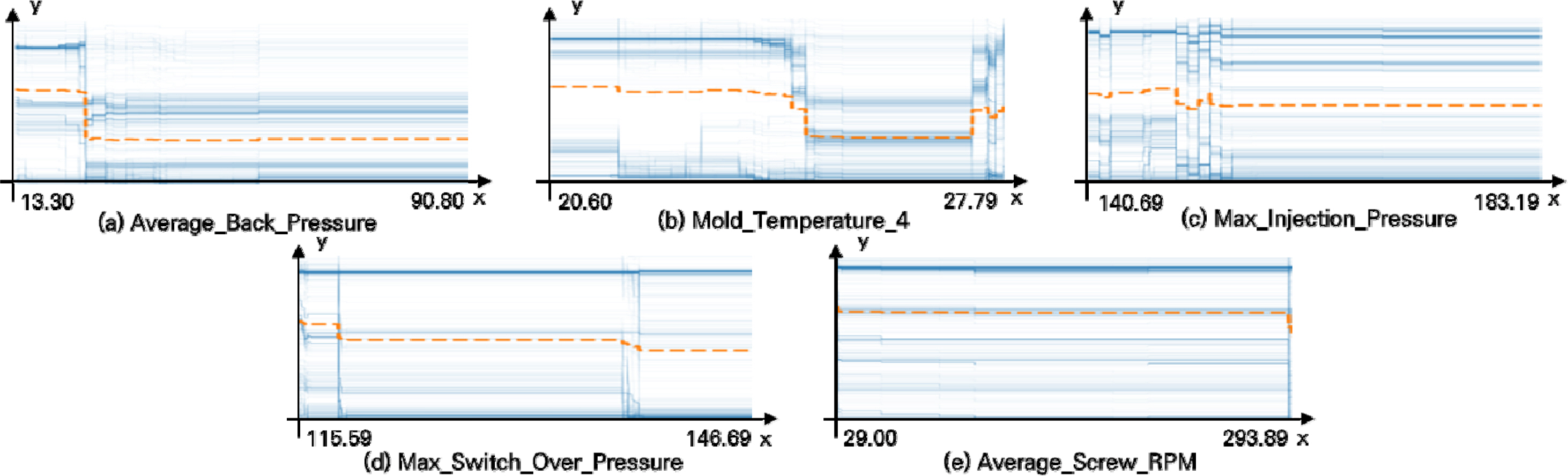
ICE Plot of LightGBM
본 연구는 양품이 될 확률이 낮은 구간을 확인하고 해당 구간에 속하지 않도록 공정을 조정하여 불량률 개선을 목적으로 한다.
4.4 유효성 검증
Train Data로 산출한 주요 변수들의 최적 범위는 Table 3, Table 4와 같다. 해당 범위에 해당하는 Test Data만을 추출하여 불량률을 비교해 봄으로써 유효성 검증을 실시한다. 각 데이터 프레임의 불량률은 다음 Table 5, Table 6과 같이 XGBoost의 경우 0.21%, LightGBM의 경우 0.29%로 기존 불량률 대비 각각 0.79%p, 0.71%p 감소한 결과를 보였다.

Control Range of XGBoost

Control Range of LightGBM
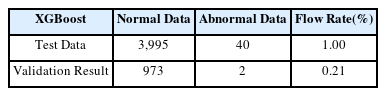
Data Constructure of XGBoost
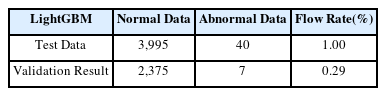
Data Constructure of LightGBM
5. 결 론
본 연구는 XAI 기반 SHAP와 ICE 기법을 사용하여 공정의 주요 변수를 추출하고, 해당 변수들의 통제 범위 규정을 통해 공정 전반의 불량률 감소를 목적으로 한다. XAI는 블랙박스 특징을 가지는 기존의 기계학습과는 달리 결괏값에 대한 근거 및 타당성을 제시하며 신뢰도를 높이는 기법으로, 해당 공정 분야 전문 지식이 없더라도 불량 개선이 가능하다는 장점이 있다. 실험은 공정데이터에 오버샘플링 등의 전처리 과정을 거친 뒤 XGBoost와 LightGBM 모델을 사용한 SHAP 기법을 통해서 주요 변수를 산출한다. 그 결과 XGBoost의 경우 6개의 주요 공정변수를, LightGBM의 경우 5개의 주요 공정변수를 선정하였다. 이후 ICE Plot을 통해 해당 변수들의 통제 범위를 산출하였다. 마지막으로 Test Data를 통해 유효성 검증 과정을 거치며 본 연구 결과를 제시하였다. 기존 불량률 1.00%에 비해 개선된 불량률은 0.21%, 0.29%로, 각각 0.79%p, 0.71%p 감소한 결과를 나타내었다.
본 실험은 사출 공정의 데이터만을 사용하여 진행하였다. 향후 연구로써 다른 공정데이터를 활용하여 본 논문의 방법론이 다양한 공정 분야에서 적용 가능한지 확인하는 추가적인 실험이 필요하다. 또한, XGBoost, LightGBM 모델 이외에 다양한 머신러닝 기법 적용 방안에 관한 추가적인 연구를 통해 방법론을 더욱 발전시킬 수 있을 것으로 보인다.