전력반도체의 수율향상을 위한 최적 공정조건 결정에 관한 연구
Process Conditions Optimizing the Yield of Power Semiconductors
Article information
Trans Abstract
Purpose
We used a data analysis method to improve semiconductor manufacturing yield. We defined and optimized important factors and applied our findings to a real-world process. The semiconductor industry is very cost-competitive; our findings are useful.
Methods
We collected data on 15 independent variables and one dependent variable (yield); we removed outliers and missing values. Using SPSS Modeler ver. 18.0, we analyzed the data both continuously and discretely and identified common factors.
Results
We optimized two independent variables in terms of process conditions; yield improved. We used DS Leak software to model netting and Contact CD software to model meshes. DS Leak shows smaller the better characterisrics and Contact CD shows normal the best characteristics
Conclusion
Various efforts have been made to improve semiconductor manufacturing yields, and many studies have created models or analyzed various characteristics. We not only defined important factors but also showed how to control processing to improve semiconductor yield.
1. 연구목표 및 배경
반도체 제조업에서 다양한 생산관련 지표 중, 생산주기(cycle time), 가동율(availability), 수율(yield)등이 주로 활용된다. 그 중 수율은 생산품 중 양품의 비율을 의미하는 것으로서, 반도체 제조업에서 회사 수익과 밀접한 관련이 있는 중요한 요소이다. 이러한 수율을 향상시키거나 현재의 수율을 유지하기 위해서 반도체 제조업에서는 다양한 공정특성을 분석하고 모형화하고 있다. 그러나 반도체 생산의 경우 매우 많은 공정변수 및 장비변수에 영향을 받아, 수율의 요인을 파악하기 매우 어렵다. 따라서, 단순한 통계적 분석이나 경험적 기술로는 수율을 향상하는데 한계를 지니고 있으며, 다양한 변동 요인을 도출하여 공정 최적화를 이루어 내야 한다.
본 연구에서는 다양한 변동요인을 고려하여 공정을 최적화하기 위해 다음과 같이 진행하고자 한다. 첫째, 데이터마이닝 기법을 통해 라인 내에서 발생되는 여러 파라미터(parameter) 중 수율에 영향을 미치는 주요 인자를 도출하였다. 둘째, 도출된 인자를 대상으로 반응표면분석법을 적용하여 최적수준을 도출하고, 끝으로 이를 생산 공정에 적용하고자 하였다.
본 연구에서는 수율을 분석하기 위하여 특정 제품을 선정하고, 이 제품의 수율에 영향을 미치는 주요 인자를 선정하기 위하여 반도체 공정의 15개 공정 파라미터 데이터를 수집하였다. 그 다음, 기존 단변량 분석인 중회귀 분석에서 벗어나 데이터마이닝 기법을 활용하여 두 가지 속성인 연속형 분석과 이산형 분석으로 가장 수율에 영향을 크게 미치는 주요 공통인자를 선정하였다. 연속형 분석으로는 선형회귀분석(linear regression), 의사결정나무분석(decision tree analysis), 인공신경망(artificial neural network)을 이용하여 분석하였다. 그러나, 구축된 모델의 적합도가 높지 않았으므로, 수율을 이산형 변수로 변환하여 추가적인 분석을 실시하였다. 고수율과 저수율을 분리하여 의사결정나무분석, 인공신경망, 로지스틱회귀분석을 통해 인자를 분류하고, 수율에 영향을 가장 크게 미치는 주요 인자를 도출하였다. 선정된 주요한 인자와 수율과의 관계를 확인하고 최적조건을 선정하기 위해 반응표면 분석방법으로 최적조건을 설정하고 이에 대한 공정조건 제어방안을 제시하고자 한다.
본 논문은 2장에서는 반도체 수율 향상과 관련된 문헌연구와 데이터마이닝을 이용한 분석방법에 대해 살펴보고, 3장에서는 반도체 공정 및 제품에 대한 소개와 연구방법 및 절차에 대해 다루었다. 4장에서는 데이터마이닝 기법을 통한 수율에 영향을 미치는 중요인자를 결정하는 방법, 그리고 반응표면 분석법을 통한 인자최적화와 이들의 현장에서의 적용 방법 등에 대해 다루었고 5장에서는 연구결과를 전체적으로 요약한다.
2. 관련 문헌연구
현재 반도체 제조공정 시스템이 자동화 되고 있으며 하루에도 수백, 수천만개의 데이터들이 생성되고 데이터베이스화 되어 실시간 공정의 상태를 파악하는데 사용되고 있다. 이렇게 수많은 데이터가 수집되고 저장되는 환경에서 단변량 통계분석 기법은 적은 양의 데이터는 정확하게 분석하지만, 데이터의 수와 인자가 증가함에 따라 분석이 어려워져 대용량 데이터 분석기법들이 대두되고 있다. 데이터마이닝기법을 활용하여 제조공정에서 발생하는 불량을 분석하고 제어하기 위한 방법들이 제안되고 있다.
데이터마이닝은 거대한 데이터베이스에서 관심이나 흥미를 가질 만한 숨겨진 관계를 찾아보는 제 2차적인 데이터 분석 기법이다(Back and Han. 2003). Yoon et al.(2019)은 종속변수에 대한 상황 정의가 없는 상황에서 딥러닝을 활용하여 시계열데이터 군집화를 통해 공정 상태를 예측하였다. Nkonyana et al.(2019)는 랜덤포레스트, 인공신경망, 서포트벡터머신을 사용하여 철강제조공정의 결함 진단을 위한 분석기법을 제안하였다. Jung et al.(2009)는 인공신경망을 이용하여 수율 개선에 영향을 많이 주는 공정을 예측하고 동시에 그 공정을 개선하기 위한 변수조정값을 예측하였다. 그리고 예측된 정보를 공정에 피드백하고 조정하여 공정의 수율을 동적으로 개선하는 모형을 제시하였다. 그러나 이러한 데이터마이닝기법이 통계학 분야에서 각광받지 못한 이유는 찾아낸 패턴들의 임의적인 현상일 수 있다는 불확실성과 최적 해를 제시하지 못한다는 이유 때문이다(Lee et al. 2005).
이러한 이유 때문에 데이터마이닝과 통계적 기법들에 대한 문제점을 해결한 방법들이 제안되고 있다. Hsu and Chien(2007)은 반도체 제조에서 특정 오류 패턴을 제시하는 웨이퍼 빈 맵(WBM:Wafer Bin Map)에서 자동으로 패턴을 빠르게 추출하여 반도체 제조의 수율을 향상시키기 위해 공간 통계와 적응적 공명이론 1 신경망(Adaptive Resonance Theory 1 neural networks)을 통합하는 하이브리드 데이터마이닝 접근법을 제안하였다. Lee and Nam(2006)은 TFT-LCD산업에서 방대한 다차원 측정 데이터로부터 변동폭이 큰 그룹을 추출하기 위해 상관분석과 최대나무(maximal tree)기법을 적용하였으며, 주된 변동 패턴을 발견하기 위해 다변량 통계분석을 이용하였다. 또한 변동의 원인 진단을 위해 제품과 조립공정 지식을 기반으로 한 의사결정나무 접근법을 사용하였다. Jung and Koo(2007)는 데이터마이닝을 이용한 로버스트 설계모형을 개발하여 제시하였다.
인자와 반응 값에 대한 인과관계 결정 및 최적화를 위해 반응표면 분석법의 방법론을 사용한 연구가 제안되었다. 반응표면 분석법은 여러 개의 인자가 복합적인 작용을 함으로써 어떤 반응변수 y에 영향을 주고 있을 때, 이러한 반응의 변화가 이루는 반응표면에 대한 통계적인 분석방법을 말한다. 일반적으로 반응표면 분석법은 정확한 함수관계를 알지 못하거나 또는 복잡할 때 입력치 x와 반응치 y의 함수 형태를 추정함으로써 이 반응치를 최적화 하는데 사용되어 진다(Jung and Koo, 2007).
반응표면분석과 관련된 연구로는 Ha et al(2012)은 LED Die 본딩 공정에 영향을 미치는 여러 인자들을 분석하고 반응표면분석법을 적용하여 얻은 결과로 실험계획법을 수립하여 공정능력을 향상시키기 위한 최적 조건을 확보하였다. Park et al(2018)은 대기오염물질 배출 허용 기준을 만족시키기 위해 반응표면법으로 미니탭 소프트웨어를 이용하여 분석한 후 질소산화물 일산화탄소에 대한 예측모형을 얻고 반응 최적화 도구를 사용하여 각 입력변수들에 대해 현재 소성공정 운전범위 내에서 최적 공정조건을 설정을 제안하였다. 또한 Lee(2004)는 다구찌의 제어 및 잡음 요인에 대한 실험에서 다중 특성 최적화 문제를 다루기 위해 다중반응 표면 모델링 및 분석 기법을 제안하였으며, Nam et al(2017)은 항공용 구조물의 신뢰성 향상을 위한 숏피닝 공정의 최적화를 위해 반응표면 분석법을 적용하여 3개 인자에 대해 알멘강도와 커버리지와의 상관관계 파악 및 최적 조건을 확보하였다.
본 연구에서는 변수와의 관련성뿐만 아니라 중요변수에 대한 최적점과 그에 대한 현장적용 방법 등을 제시한다. 또한 데이터마이닝 기법을 활용하여 수율을 연속형 변수와 이산형 변수로 전환하여 수율에 영향을 주는 가장 중요한 인자를 예측하였다. 예측된 인자들에 대한 최적조건을 반응표면분석법을 사용하여 도출하고 이에 대한 공정제어 방안을 제시하여 수율개선에 최대 효과를 얻는 모형을 도출하는데 그 의미를 찾고자 한다.
3. 연구방법 및 절차
3.1. 연구대상 제품소개
본 연구에 활용된 제품은 전력반도체에 적용되는 비메모리 반도체 제품을 대상으로 연구하였다. 전력반도체는 전력용 파워스위칭 소자와 제어 집적 회로(IC:integrated circuit)로 구성되어 전자기기에 들어오는 전력을 그 전자기기에 맞게 전력을 변환, 분배 및 관리하는 역할을 한다. 일반반도체에 비해서 고내압화, 고신뢰성화 등이 요구되며 컴퓨팅, 통신, 가전, 산전 및 자동차등 오늘날 중추적인 전자 어플리케이션에 적용되고 있다. 최근에 고속스위칭, 전력손실 최소화, 발열처리 등에 관한 연구개발로 전력반도체는 디스플레이, 드라이브 집적 회로, 휴대용기기, 가전기기, 신재생/대체에너지, 자동차 등에 사용되는 각종 부품의 친환경화 및 에너지 절감화에 크게 기여하고 있다. 또한 IT기기의 성능을 향상시키고 절전기능을 강화하여 친환경 절전형 전력반도체 기술 개발이 요구되고 있다.
여기서 사용되는 복합고전압소자(BCDMOS: Bipolar CMOS DMOS)공정은 바이폴라 공정을 활용한 아날로그 회로와 CMOS공정을 활용한 로직회로, DMOS공정을 활용한 고전압소자를 하나의 칩에서 구현할 수 있도록 해주는 반도체 제조공정이다. 현재 전력용량이 소용량이며 스위칭 속도가 빠른 응용분야에는 파워 모스펫(MOSFET)소자가 가장 많이 사용된다. 전력용량이 중용량이며 스위칭 속도가 중간인 응용분야에는 모스펫과 바이폴라의 장점만 가지는 고전력스위칭용반도체(IGBT:Insulated Gate Bipolar Transistor)소자가 많이 사용되고 있다.
기술 응용분야에는 0.35um/60V급 BCD 공정기술에는 모바일용 전원관리집적회로(PMIC:Power Management Integrated Circuit), 디스플레이 구동칩(DDI:Display Driver IC)등에 사용되고 0.18um/60V급 공정기술에는 모바일용 전원관리집적회로, 디스플레이 구동칩, LCD TV등의 제품에 응용되고 있다.
전력용 반도체는 과거 개별 소자 또는 제어 집적 회로를 중심으로 개발되어 왔으나 휴대용 기기, 디스플레이 기기와 같은 다양한 멀티미디어 기기의 성장에 따라서 주문형 반도체(ASIC:Application Specific Integrated Circuit) 또는 ASSP 형태의 파워 매니지먼트 집적회로를 중심으로 개발되고 있으며 시스템 내에서 그 역할이 계속 커지고 있다. 파워 매니지먼트 집적 회로의 기술 개발 방향은 적용하는 시스템에 따라 조금씩 다르나 전반적인 추세는 서브마이크론 BCD(Bipolar/CMOS/DMOS) 공정 개발을 통한 고집적화 및 유사 기능을 중심으로 다양한 기능을 통합해가는 임베디드 방식으로 발전하고 있다. Figure 1은 전력반도체의 응용분야를 도시한 것이다.

Power Semiconductor application field
3.2. 연구모형 및 변수설정
본 연구의 프로세스는 Figure 2와 같으며 데이터를 수집 후 이상치나 결측치를 제거하기 위한 데이터 전처리 과정을 거친 후 분석 모델링을 통해 인자를 도출하고 이를 최적화하여 최종적으로 공정제어의 프로세스로 진행되었다.

Research Flow Chart
데이터 수집은 반도체 제조공정에서 실측된 데이터로 분석하였다. 데이터 전처리 단계에서는 실제 데이터는 불완전(incomplete), 잡음(noisy), 불일치(inconsistent)가 존재하므로 데이터의 전처리가 필요하다. 일반적으로 데이터 전처리 단계에서는 데이터 중 결측치를 채워넣고 잡음이 있는 데이터를 제거하며 이상치를 식별하고, 데이터 불일치를 교정한다. 본 연구에서는 데이터의 이상치 및 결측치에 대해 해당 레코드를 삭제하여 데이터 불완전성에 대해 문제점을 제거하였다. 모델링 단계에서는 SPSS Modeler 18.0을 활용하여 노드를 구성하였다. 모형을 평가하기 위해 연속형 분석은 선형회귀, 의사결정나무분석(C 5.0), 인공신경망을 이용하였다. 그러나, 연속형 분석을 통해 구축된 모델의 적합도가 높지 않았으므로, 수율을 이산형 변수로 변환하여 추가적인 분석을 실시하였다. 이산형 분석은 고수율과 저수율을 분리하여 의사결정나무분석(C 5.0), 인공신경망, 로지스틱회귀분석을 통해 중요인자를 선정하였다. 인자들에 대한 최적조건 설정을 위해 반응표면분석법을 사용하여 인자의 최적조건을 규명하고 마지막으로 선정된 중요인자에 대해 최적의 수율을 확보할 수 있는 공정제어를 구현하는 방법을 제시하고자 한다.
각 로트가 증착, 사진, 식각, 주입등 단위공정을 진행한 후에는 해당 단위공정이 원하는 스팩(Specification)으로 적절히 진행되었는지 확인하기 위해 계측장비를 통해 임계치수(CD:Critical Dimension), 두께(Thickness)등을 계측한다. 계측된 데이터는 자동으로 데이터베이스에 저장된다. 데이터 분석을 위해 수율에 영향을 줄 수 있는 주요한 15개의 독립변수와 1개의 종속변수를 선정하였고 데이터 수집은 로트단위로 수집된 데이터를 기준으로 하였다. 수집된 데이터에 대한 개략설명은 Table 1과 같다.

Process variables
3.3. 모델링
본 연구에서 사용된 모델링은 데이터마이닝 SPSS Modeler 18.0을 사용하였다. 입력노드는 국내 A반도체 제조업체에서 생성된 수율과 연계된 반도체 제조공정에서의 공정변수를 대상으로 분석하였다. 유형노드에서는 연속형과 이산형으로 분리하여 구성하였으며 연속형의 경우 종속변수를 수율로 놓고 15개 인자들을 독립변수로 지정하였다. 이산형의 경우는 종속변수인 수율을 목표값이 93% 이상인 경우 양품으로 93%미만인 경우는 불량으로 분류하여 분석을 진행하였다. 연속형 분석은 선형회귀, 의사결정나무분석(C5.0), 인공신경망분석을 수행하였고 이산형 분석은 의사결정나무분석(C5.0), 인공신경망분석, 로지스틱 회귀분석을 수행하였다. 선형회귀의 경우 연속형 종속변수와 독립변수와의 관계를 수학적 모델인 선형 회귀방정식을 이용하여 인자와의 관계를 규명하는 분석 모델링이다. 인공신경망은 다중레이어 퍼셉트론을 통해 생성된 은닉층을 내재하고 있는 모델이다. 의사결정나무 분석 중 C 5.0을 사용하여 분석을 시행하였다. C 5.0은 정보이득율을 사용하여 변수들의 결과들에 대해 정보의 이익 비율이 최대화 되는 점에서 데이터의 분할을 선택한다. 가지 쳐진 노드와 그렇지 않은 가지의 예측 오차를 비교하여 의사결정나무 모델을 생성한다. 정보이득율은 분류를 통해 정보를 얻은 정도를 의미한다. 즉, 엔트로피 감소, 불순도 감소, 순수도의 증가가 가장 많이 일어난 분류기준을 선택한다. 로지스틱 회귀분석 노드는 2개 이상의 이산형 값을 갖는 종속변수와 독립변수들 간의 인과 관계를 로짓함수를 이용하여 추정하는 모델링 노드이다.
분석노드는 모델의 분류성능을 평가하는데 사용하며 연속형의 경우 선형상관관계를 통해 종속변수와의 관계를 설명한다. 이산형의 경우 정확성 척도를 사용하여 분류행렬(classification matrix)로부터 예측값이 목표값에 얼마나 정확한지를 예측 비교한다. 평가노드는 ROC곡선(receiver operating characteristic curve), 이익도표등 예측모형의 정확성을 평가하는데 활용된다.
4. 실험분석 및 결과
4.1. 연속형분석(선형회귀, 의사결정나무분석(C 5.0), 인공신경망)
본 연구에서는 연속형분석을 통한 중요인자를 선정하기 위해 선형회귀, 의사결정나무분석, 인공신경망 기법을 활용하여 분석하였다. 인자선정의 주요 항목은 각 분석에서 예측변수 중요도를 통해 우선순위가 높은 항목에서 선정하였으며 모델의 정합성은 선형상관관계를 통해 확인하였다. 그에 대한 비교결과는 Table 2와 같다.

Continuous data analysis result
선형상관관계를 분석한 결과 선형회귀는 0.795, 의사결정나무분석은 0.6, 인공신경망분석은 0.694로 선형회귀의 상관관계가 가장 높은 것으로 나타나서 모델의 적합성은 선형회귀가 가장 적합한 것으로 확인된다.
중요인자의 경우 선형회귀에서는 DS Leak와 Contact CD, Hardmask Etch CD로 3개의 인자가 유의한 인자로 선정되었으며 의사결정나무분석과 인공신경망 분석에서는 DS Leak, Contact CD 2개의 인자가 예측변수 중요도에서 높은 인자로 선정되었다. 결과적으로 3개의 분석 방법을 비교해보면 선형회귀분석이 모델링으로서는 가장 적합한 모델링이며 인자는 공통적으로 DS Leak와 Contact CD가 주요한 인자임을 알 수 있다.
아래 Table 3은 의사결정나무분석에서 분석된 수율에 대한 결정규칙 중 최상위 규칙에 대한 평균 수율값과 해당 데이터의 개수, 전체 데이터 중 해당 데이터의 비율을 보여주고 있다. 여기에서 Contact CD는 0.5536이상이고 DS Leak가 0.29이하이면 최소한 93.72% 이상의 수율을 얻을 수 있음을 조건으로 보여주고 있으며 Figure 4는 인공신경망에서 도출된 예측변수 중요도에 대한 그래프 해석을 보여주고 있다. 그러나, 연속형 분석 결과, 모델의 적합도가 높지 않아 이산형분석을 추가적으로 진행하였다.

Top Level Decision Rule
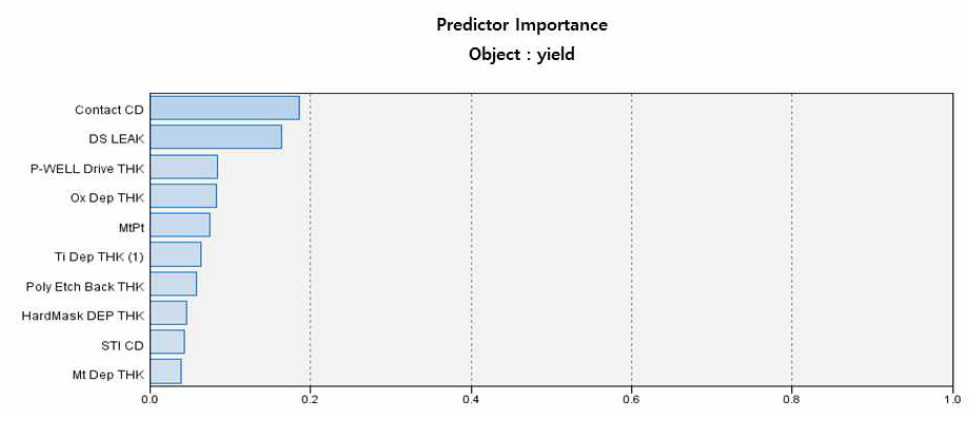
Neural Network Predictive Variables Importance
4.2. 이산형분석(의사결정나무분석(C 5.0), 인공신경망, 로지스틱회귀분석)
이산형분석에서는 의사결정나무분석, 인공신경망분석, 로지스틱회귀분석을 사용하였으며 분류 행렬표를 통하여 정확도와 에러율을 비교하였다. 이산형 데이터 분석을 위해 수율의 데이터를 목표 타겟인 93%를 기준으로 93이상은 양품으로, 93미만인 경우는 불량으로 분류하였다. 그에 대한 수행 결과는 Table 4, Table 5와 같다.
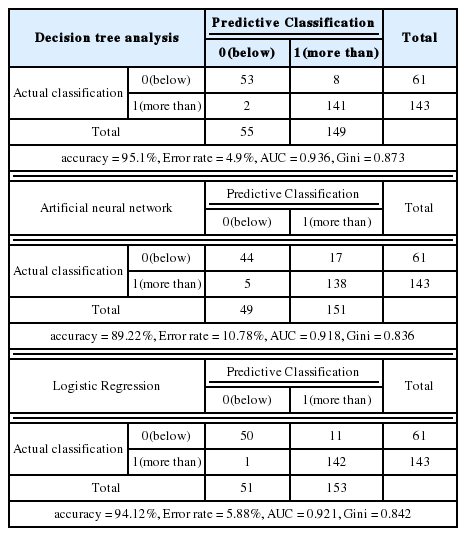
Decision tree analysis, Neural network, Logistic regression confusion matrix table
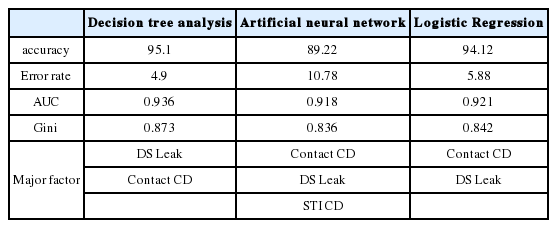
Comparison of classification matrix table results of each technique
데이터에 대한 분석결과 정확도 부분에서는 의사결정나무분석이 95.1%, 인공신경망이 89.22%, 로지스틱회귀분석이 94.12%로 의사결정나무분석에서 가장 높은 정확도를 보이며 에러율에서는 의사결정나무분석이 4.9%, 인공신경망이 10.78%, 로지스틱회귀분석은 5.88%로 의사결정나무분석에서 가장 낮은 값을 보이고 있다. 세 분석 모두 높은 정확도를 보이고 있으나 의사결정나무분석이 정확도, 에러율 뿐만아니라 모델의 정합성을 판정하는 AUC와 지니(gini)계수에서도 높은 값을 보이고 있다. 여기서 AUC는 판별력의 측도로, ROC 곡선 아래의 면적이 넓은 모형은 모형이 관측치 반응의 값을 정확하게 예측할 수 있다는 것을 나타낸다. AUC가 0.9이상이면 최고의 판별력을 의미한다. 지니지수는 불순도를 측정하는 지표로서 보통 0.8이상이면 높은 불순도를 의미한다. 주요인자에 대한 효과는 의사결정나무분석에서는 DS Leak가 다른 인자에 비해 영향도가 압도적으로 높으며 인공신경망과 로지스틱 회귀분석에서도 인자의 중요도는 DS Leak와 Contact CD가 중요한 이자로 공통적으로 분류되고 있다. 의사결정나무의 예측변수 중요도와 그림은 Figure 5과 Figure 6로 다음과 같다.
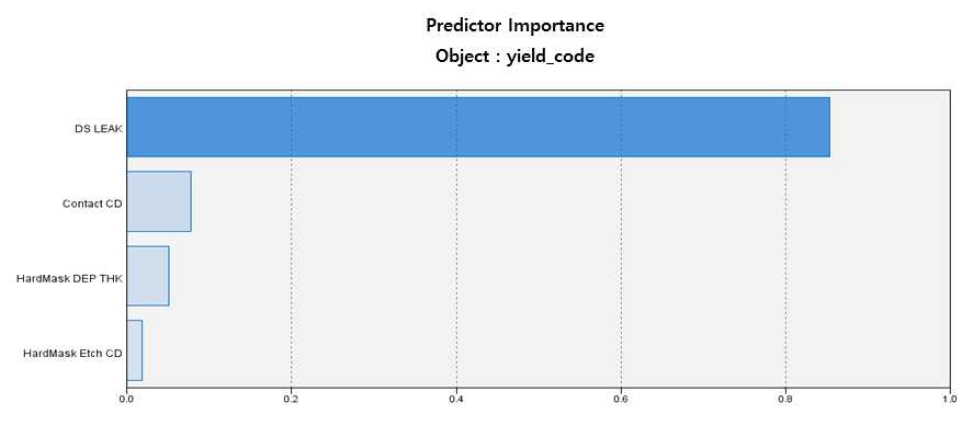
Decision Tree Predictive Variables Importance

C5.0 Decision Tree
4.3 공정최적화
위에서 선정된 수율에 영향을 주는 공통인자를 DS Leak와 Contact CD에 대한 최적조건을 찾기 위하여 반응표면분석을 실시하였다. 실험에 대한 계획방법으로 현 문제에 대해 실험을 어떻게 실시하고, 데이터를 어떻게 취하며, 어떤 통계적 방법으로 데이터를 분석하면 최소 실험으로 최대 정보를 얻고자 계획하는 것을 실험계획법이라 정의하고 있으며 반응표면분석법은 하나 또는 그이상의 반응변수와 독립변수와의 관계를 규명하는데 사용되는 실험 설계 방법으로 반응변수를 최적화 할 수 있는 인자의 조건을 찾는데 사용된다.[10] 분석툴은 미니탭 18.0을 사용하였다. 반응표면 분석결과에 대한 분산분석 결과와 요약은 아래 Table 6과 Table 7에 정리되었다.

Variance Analysis for Response Surface Analysis

Model summary of Variance Analysis for Response Surface Analysis
분산분석 테이블을 해석해 보면 DS Leak와 Contact CD는 수율에 선형관계의 영향을 주고 있으며 특히 Contact CD의 경우 곡선형의 효과도 있음을 알 수 있다. R-제곱값의 경우 약 60% 정도로 나타나고 있어 인자에 대한 설명력이 다소 높다고 볼 수 있다. 인자들에 대한 최적 조건을 도출하기 위해 등고선도와 반응최적화 도구를 사용하였다. 이에 대한 그림은 Figure 7과 같다.

Yield curve according to factor condition
인자들에 대한 최적조건은 등고선도를 살펴보면 DS Leak는 작을수록 좋고 Contact CD의 경우는 0.56 ~ 0.58 범위에서 높은 수율을 가질 수 있으며 반응최적화 그림을 통해 확인해 보면 최적의 수율은 DS Leak 0.4와 Contact CD 0.5776에서 최적의 수율값인 94.84%의 수율을 얻을 수 있다.
위의 결과를 통하여 DS Leak는 0.4이하로 관리하고 Contact CD의 경우는 공정제어 범위를 0.57 ± 0.02로 제어할 필요가 있다.
4.4 공정제어
반응최적화 분석법을 통하여 DS Leak와 Contact CD에 대한 최적의 관리범위를 설정하였다. 여기서 DS Leak는 관리의 특성치로 구분할 수 있다. DS Leak에 영향을 주는 요소는 웨이퍼(wafer)의 특성뿐만아니라 불순물(Implant)의 농도와 에너지, 옥사이드두께, 열공정 등 다양한 요소에 의해 영향을 받는 인자이므로 이를 제어하기 위해서는 추가적인 분석이 필요하다. 이에 대한 분석 및 제어는 담당공정 엔지니어를 통해 관리될 수 있도록 하였고 두 번째 제어인자는 Contact CD에 대한 제어를 제안하고자 한다.
Contact 공정은 반도체 기판과 금속을 연결시키는 공정으로 일반적으로 반도체 제조 공정에서 전공정과 후공정을 나누는 공정이기도 하다. 접촉(Contact)공정은 반도체 기판에 게이트가 형성되고 메탈과 격리(isolation)시키기 위해서 BPSG로 증착(deposition)하고 여기에 포토(photo) 패턴을 형성하여 옥사이드 에칭을 진행하여 형성한다. 이때 형성된 포토패턴 임계치수와 접촉 식각(contact etch) 임계치수는 일정값으로 편의(bias)가 형성되므로 패턴 임계치수를 조절함으로써 etch 임계치수를 결정할 수 있다. 이에 대한 모습을 식1로 다음과 같이 표현할 수 있다.
본 연구에서 사용되는 식각장비는 TEL(Tokyo Electron)사의 DRM(Dipole Ring Magnet) 장비로 플라즈마(plasma)를 활용하여 식각을 진행한다. 플라즈마상에서 옥사이드 식각을 수행하기 위해 주로 사불화탄소(CF4), 플루오로포름(CHF3), 옥타플루오로사이클로뷰테인(C4F8)등과 같은 높은 탄소/불소 비율의 가스를 활용하여 식각을 수행하고 규소(Si)와 선택비를 10이상을 가질 수 있도록 레시피를 구성하고 규소의 손상을 최소화 할 수 있도록 공정이 종결될 때는 엔드포인트(endpoint)를 통해서 확인할 수 있도록 구성되어 있다.
이러한 장비를 이용하여 Contact 임계치수를 확보할 수 있는 프로세스는 아래 그림으로 표현하였으며 Figure 8은 접촉식각 프로세스에 대한 그림이고 Figure 9는 접촉식각 후 SEM이미지 사진이다.
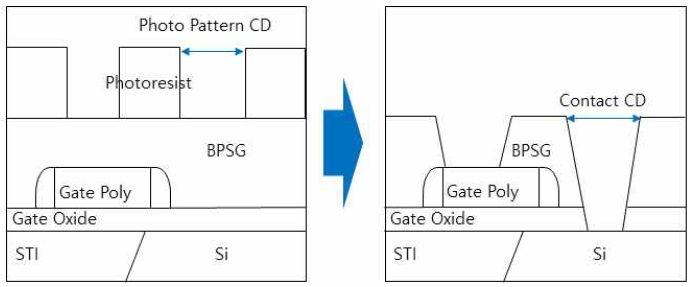
Contact Etch Process
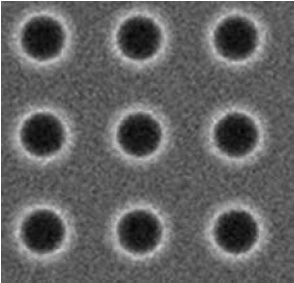
Contact SEM image
5. 결론
반도체 제조업에서 공정의 수율을 확보하는 것은 매우 중요하다. 이를 위해 본 연구에서는 반도체 공정에서 수율에 영향을 주는 주요인자를 도출하였다. 데이터 분석 기법의 특성에 따라 인자에 대한 해석은 차이를 가질 수 있다. 이로 인하여 특정 분석기법에 한정하여 데이터를 분석하였을 때는 불필요한 인자를 중요인자로 선택하거나, 중요한 인자를 놓치는 우를 범할 수 있다. 이러한 문제를 피하기 위하여 다양한 분석기법을 활용하여 주요인자가 무엇인지를 확인하였다. 연속형 분석방법으로는 선형회귀분석, 의사결정나무분석, 인공신경망 기법을 활용하여 분석하였으며 선형상관관계를 통하여 인자의 중요도를 결정하였다. 그러나 모델의 적합도가 높지 않아 이산형 분석을 수행하였다. 이산형 분석방법으로는 C5.0, 인공신경망, 로지스틱회귀분석 기법을 활용하여 분석을 수행하였고 정확도, 에러율, AUC, Gini계수 등을 이용하여 인자의 중요도를 결정하였다.
각각의 분석 기법에 따라 2~3개의 주요인자가 도출되었으며 도출된 인자 중 연속형분석과 이산형분석에서 공통적으로 2개의 인자가 주요한 인자로 선택되었다. 선택된 2개의 인자는 DS Leak와 Contact CD로서 이들 독립변수가 종속변수인 수율에 대한 영향도가 가장 큰 것으로 확인되었다. 이들 독립변수에 대한 수율 영향도의 최적 조건을 확인하기 위하여 반응표면분석법을 활용하여 최적조건을 추정하였을 때 DS Leak는 0.4이하로 제어하고 Contact CD의 경우는 공정제어 범위를 0.56 ± 0.02로 하였을 때 최적의 수율값을 얻을 수 있다는 최적조건을 얻을 수 있었다.
이러한 결과를 근거로 각 공정에서 제어할 수 있는 방향을 설정하여 최적의 수율을 확보할 수 있는 제어방안을 제시하였다. Contact을 형성하는 산화 식각(Oxide Etch)공정에서는 포토 패턴 CD로부터 일정 편의 만큼 변화되는 특성을 감안하여 Photo 패턴을 형성하는 공정에서 일정 제어범위를 설정하여 노광을 진행함으로써 최적의 수율을 얻을 수 있는 CD를 형성해주는 방법을 제안하였다. DS Leak의 경우 불순물의 농도와 열공정과 같은 여러 공정의 조합에 의해 발생되는 현상이므로 이를 제어하는 방법보다는 모니터링을 통해 관리할 수 있는 방안을 강구하는 것이 더 바람직하다 할 수 있다. 본 연구에서는 급속도로 변하는 반도체 산업의 제조공정에서 수율을 관리하고 개선하는데 있어 보다 더 실용적이고 과학적인 기법이라고 사료된다.